LLMエージェントやチャットアプリを作っていると、かなり早い段階で「過去の会話をどう覚えさせるか」という問題にぶつかります。
最初に思いつくのは、過去ログをそのまま入れる方法です。 しかし、これはトークン数が増え料金が増えるというだけではなく、長い入力を与えても、LLMがその中の情報を安定して使えるとは限らないという問題がでてきます。
この点を示したものに、Lost in the Middle: How Language Models Use Long Contexts があります。この論文では、関連情報の位置を変えるとモデルの性能が大きく変わること、特に重要な情報が入力の最初や最後にあるときは比較的使いやすい一方で、長いコンテキストの中間にあると性能が大きく下がることが報告されています。つまり、過去ログを全部入れればよい感じに処理してくれる、というわけにはいかないです。(arXiv)
そこを工夫したのが、A-MEM: Agentic Memory for LLM Agents です。 A-Mem は、過去ログをただ長く保存して、必要そうなものを検索するのではありません。会話や経験を「記憶ノート」として保存し、そのノート同士に関連性を付け、新しい記憶が入ったときには古い記憶の文脈も更新します。論文では、Zettelkasten という考え方をもとに、dynamic indexing、linking、memory evolution を行う memory system として説明されています。(arXiv)
この記事では、A-Mem が何を解決しようとしているのか、どのように記憶をノート化し、関連づけ、更新しているのか、そして LLMアプリやエージェント開発にどう応用できるのかを整理します。
参考にしたもの
- A-MEM: Agentic Memory for LLM Agents 2025/02/17
- 関連論文: Lost in the Middle: How Language Models Use Long Contexts
- 論文再現用コード: WujiangXu/A-mem
- 実装向けメモリシステム: WujiangXu/A-mem-sys
WujiangXu/A-mem は、README で論文結果を再現するためのリポジトリと説明されており、実際にエージェント構築で A-Mem を使いたい場合は A-mem-sys を参照するよう案内されています。A-mem-sys 側では、ChromaDB による記憶保存、LLM による keywords / context / tags の生成、関連記憶の分析、dynamic linking、memory evolution などが説明されています。(GitHub)
Contents
- 結論
- まず、何が問題なのか
- 図1:従来のメモリと A-Mem は何が違うのか
- Zettelkasten とは何か
- 図2:A-Mem はどう動くのか
- 数式でみる A-Mem
- 図3:記憶をいくつ取り出すべきか
- 図4・図5:記憶表現はどう整理されるのか
- 実装するとしたらどう作るか
- どこに応用できるのか
- 注意点
- まとめ
結論
A-Mem は、LLMエージェントの記憶を 「保存された過去ログ」から「関連づけられて育つ記憶ノート網」へ変える設計です。
従来のメモリでは、過去の会話や行動履歴は、基本的には記録された順に蓄積されます。検索時には embedding などを使って、今の質問に近そうな記録を取り出します。 しかし、そのままでは、記録同士の関係は明示されません。
たとえば、過去に次のようなログがあったとします。
- 「論文解説では、知らない単語を先に説明してほしい」
- 「急に A-Mem という単語が出てきて困った」
- 「概要の前に前提知識を置いてほしい」
- 「順番に考えながら説明してほしい」
従来のメモリでは、これらは別々のログとして保存されます。 検索すればいくつかは見つかるかもしれません。 しかし、それらをまとめて、
このユーザーは、論文解説では未知語を先に定義し、前提から順番に積み上げる説明を好む
という理解にするには、ログ同士の関連性を明示的に扱う必要があります。
A-Mem はここに踏み込みます。 記憶をただ保存するのではなく、context、keywords、tags を持つノートとして保存し、関連する記憶同士にリンクを張り、新しい記憶によって古い記憶の文脈も更新します。論文では、A-Mem は basic storage and retrieval を超えて、記憶を動的に組織化する agentic memory system だと説明されています。(arXiv)
一言でいうと、A-Mem はこうです。
LLMエージェントの記憶を、単なる過去ログ検索から、育っていく知識ネットワークに変える仕組みです。
まず、何が問題なのか
LLM に長期記憶を持たせる方法として、もっとも単純なのは過去ログをそのまま入れることです。
しかし、これには大きな問題があります。
1つ目は、入力が長くなるほどコストや遅延が増えることです。 ただし、これは分かりやすい問題です。
より重要なのは、2つ目です。 長いコンテキストに情報を入れても、モデルがその情報をうまく使えるとは限らないことです。
Lost in the Middle では、長い入力の中で関連情報の位置を変えるとモデルの性能が大きく変わることが示されています。特に、重要情報が入力の最初や最後にあるときは比較的性能が高く、中間にあると性能が落ちやすいと報告されています。(arXiv)
これは、長期記憶システムを作るうえでかなり重要です。
なぜなら、過去ログを大量に入れる方式では、重要な情報がコンテキストの中間に埋もれやすいからです。 「全部入れたから大丈夫」ではなく、「全部入れたせいで、むしろ大事なものが見えにくくなる」可能性があります。
次に考えられるのが、embedding 検索です。
過去ログを保存する
↓
embedding を作る
↓
今の質問に近いログを検索する
↓
LLM に渡す
これはかなり有効です。 ただし、単純な embedding 検索にも弱点があります。
それは、ログ同士の関係が分からないことです。
たとえば、以下の3つの記録があったとします。
記憶A:ユーザーは論文解説で用語説明を先に欲しがった
記憶B:ユーザーは A-Mem という単語を知らなかった
記憶C:ユーザーは概要の前に前提知識が欲しいと言った
検索すれば、記憶Aや記憶Cは見つかるかもしれません。 しかし、これらが同じ「説明スタイルの好み」に属する記憶であることは、単純な保存だけでは分かりません。
A-Mem は、この問題に対して、
記憶をノート化する
記憶同士をリンクする
新しい記憶で古い記憶の説明も更新する
という方法を取ります。
図1:従来のメモリと A-Mem は何が違うのか

図1. 従来のメモリシステムと A-Mem の違い 出典: A-MEM: Agentic Memory for LLM Agents
従来のメモリでは、過去の記録は基本的に記録された順に保存され、検索対象として蓄積されるデータとしてこのように扱われます。
ログ1
ログ2
ログ3
ログ4
...
もちろん、embedding 検索を使えば、今の質問に近いログを取り出すことはできます。 しかし、それぞれのログ同士が、
ログ1 と ログ3 は同じユーザー嗜好に関係する
ログ2 は ログ4 の原因になっている
ログ5 は過去のログ1をより具体化している
といった形で明示的につながっているわけではありません。
A-Mem は、この部分を変えます。
A-Mem では、過去ログをただの時系列データとして保存するのではなく、記憶ノートとして保存します。 さらに、似ている記憶や関係する記憶を探してリンクを張ります。 そして、新しい記憶が入ったとき、関連する古い記憶の context、keywords、tags を更新します。
つまり、従来のメモリがこうだとすると、
記録A
記録B
記録C
記録D
A-Mem はこうです。
記憶A ── 関連 ── 記憶C
│ │
│ └── 具体化 ── 記憶D
│
└── 同じ嗜好 ── 記憶B
この図で見るべきポイントは、 A-Mem は「過去ログを取ってくる仕組み」ではなく、「過去ログ同士の関係を作る仕組み」だということです。
ここが、ただの RAG 的メモリとの大きな違いです。
Zettelkasten とは何か
A-Mem の発想元として出てくるのが Zettelkasten です。
Zettelkasten は、1つのノートに1つの考えを書き、それらをリンクして知識ネットワークとして育てていくノート術です。 最初は小さなメモでも、別のメモとつながることで、あとから新しい意味が見えてきます。
A-Mem は、この考え方を LLMエージェントの記憶に応用しています。論文でも、Zettelkasten の基本原則に従って、interconnected knowledge networks を作る memory system を設計したと説明されています。(arXiv)
普通のチャット履歴は、長い巻物のようなものです。
1月1日の会話
1月2日の会話
1月3日の会話
...
一方、A-Mem の記憶は、カード型のノートに近いです。
{
"content": "ユーザーは、論文解説では専門用語を先に説明してほしいと言った。",
"timestamp": "2026-04-26T10:30:00+09:00",
"keywords": ["論文解説", "専門用語", "事前説明"],
"tags": ["user_preference", "paper_explanation", "explanation_style"],
"context": "ユーザーは、未知語を先に定義してから説明するスタイルを好む。",
"links": ["mem_104", "mem_251"],
"embedding": "..."
}
ここで重要なのは、content だけではありません。
A-Mem は、記憶に対して、
この記憶は何についての記憶なのか
どんなキーワードで探せるのか
どんなタグに分類できるのか
他のどの記憶と関係するのか
を付けていきます。
記憶を「文章」ではなく、「あとで使える知識ノート」として保存するわけです。
図2:A-Mem はどう動くのか
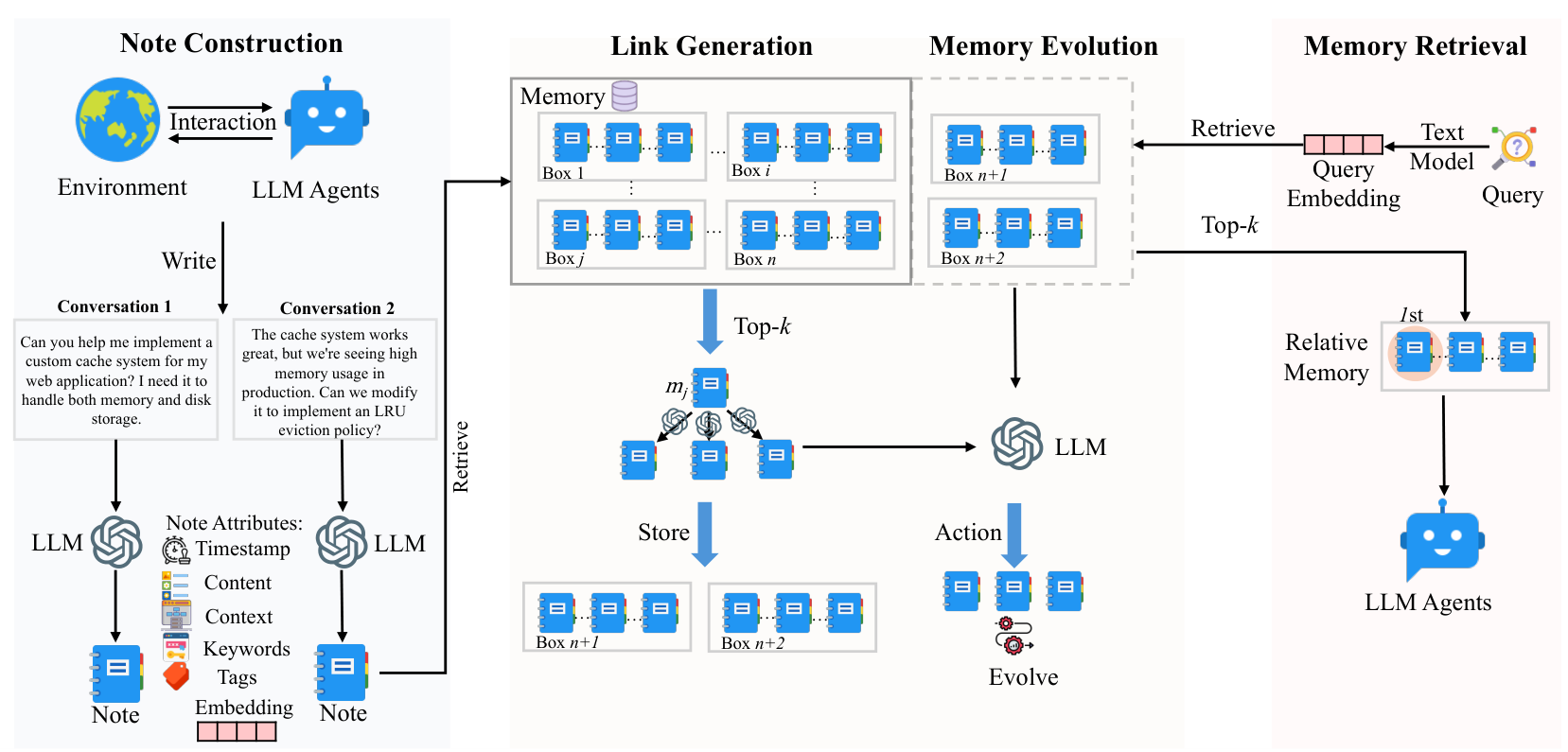
図2. A-Mem の全体フレームワーク 出典: A-MEM: Agentic Memory for LLM Agents
A-Mem の処理は、大きく4つに分けると分かりやすいです。
Note Construction
↓
Link Generation
↓
Memory Evolution
↓
Memory Retrieval
1. Note Construction
まず、新しい会話や経験をそのまま保存するのではなく、記憶ノートに変換します。
たとえば、
ユーザーは、論文解説では専門用語を先に説明してほしいと言った。
という会話ログがあったとします。
A-Mem では、これを次のように変換します。
{
"content": "ユーザーは、論文解説では専門用語を先に説明してほしいと言った。",
"keywords": ["論文解説", "専門用語", "事前説明"],
"tags": ["user_preference", "explanation_style"],
"context": "ユーザーは、論文解説において未知語を先に定義する説明を好む。"
}
論文では、新しい memory が追加されると、contextual descriptions、keywords、tags などの structured attributes を持つ comprehensive note を生成すると説明されています。(arXiv)
2. Link Generation
次に、過去の記憶の中から関連しそうなものを探します。
たとえば、過去に以下の記憶があったとします。
記憶A:ユーザーは、説明が急に専門用語から始まると読みにくいと言った。
記憶B:ユーザーは、概要の前に前提知識を置いてほしいと言った。
記憶C:ユーザーは、論文の次に読むべき論文も知りたいと言った。
新しい記憶が「専門用語を先に説明してほしい」なら、記憶Aや記憶Bとは強く関係しそうです。
A-Mem は、こうした関係を見つけ、記憶同士にリンクを張ります。
A-mem-sys の README でも、過去記憶との relationship analysis を行い、content と metadata の類似性に基づいて meaningful links を作ると説明されています。(GitHub)
3. Memory Evolution
ここが A-Mem の一番おもしろいところです。
新しい記憶が追加されたとき、A-Mem は関連する古い記憶も更新します。
たとえば、古い記憶がこうだったとします。
古い記憶:
ユーザーは論文説明に不満がある。
context:
論文説明に不満がある。
その後、次のような記憶が増えます。
ユーザーは専門用語を先に説明してほしい。
ユーザーは概要の前に前提知識を置いてほしい。
ユーザーは急に知らない単語が出ると止まる。
すると、古い記憶の context は、次のように更新できます。
更新後のcontext:
ユーザーは論文解説において、未知語を先に定義し、前提知識から順番に説明する形式を好む。
これは、単なる要約ではありません。 複数の記憶から、より使いやすい文脈表現に進化させています。
論文でも、新しい記憶が統合されると、関連する過去記憶の contextual representations や attributes が更新され、memory network が理解を継続的に洗練すると説明されています。(arXiv)
4. Memory Retrieval
最後に、ユーザーが質問したとき、A-Mem は関連する記憶を取り出します。
ただし、ここで取り出される記憶は、単なる生ログではありません。 すでに Note Construction、Link Generation、Memory Evolution を通った記憶です。
つまり、A-Mem の retrieval は、
過去ログから似た文章を探す
ではなく、
整理済みの記憶ネットワークから、今必要な記憶を探す
に近いです。
数式でみる A-Mem
A-Mem の考え方は文章だけでも分かりますが、数式で見ると設計の意図がよりはっきりします。
記憶ノート
A-Mem の記憶ノートを、次のように考えます。
m_i = {c_i, t_i, K_i, G_i, X_i, e_i, L_i}
それぞれの意味はこうです。
| 記号 | 意味 |
|---|---|
| (c_i) | 記憶の本文 |
| (t_i) | タイムスタンプ |
| (K_i) | キーワード |
| (G_i) | タグ |
| (X_i) | 文脈説明 |
| (e_i) | embedding |
| (L_i) | 関連記憶へのリンク |
ここで重要なのは、記憶がただの文章ではないことです。
本文
+
キーワード
+
タグ
+
文脈説明
+
リンク
を持つ、構造化されたノートになっています。
embedding の作り方
検索用の embedding は、本文だけでなく、keywords、tags、context も合わせて作ると考えると分かりやすいです。
e_i = f_{\mathrm{enc}}(\mathrm{concat}(c_i, K_i, G_i, X_i))
これは、
本文だけをベクトル化する
のではなく、
本文 + キーワード + タグ + 文脈説明をまとめてベクトル化する
という意味です。
つまり、A-Mem は検索前に、記憶に「検索しやすい意味のラベル」を付けています。 これは、図書館で本をただ棚に置くのではなく、タイトル、分類、要約、関連本情報を付けてから置くようなものです。
類似度の計算
新しい記憶 (m_n) と、過去の記憶 (m_j) の近さは、コサイン類似度で考えられます。
s_{n,j} = \frac{e_n \cdot e_j}{|e_n||e_j|}
これは、2つの embedding がどれくらい近い方向を向いているかを見る式です。
値が大きければ、意味的に近いとみなせます。
ただし、A-Mem はここで終わりません。 単に近い記憶を取るだけではなく、その記憶同士が本当に関係するのか、どういう関係なのかを考え、リンクや更新に使います。
質問時の retrieval
ユーザーの質問 (q) が来たら、質問も embedding にします。
e_q = f_{\mathrm{enc}}(q)
そして、各記憶との類似度を計算します。
s_{q,i} = \frac{e_q \cdot e_i}{|e_q||e_i|}
上位 (k) 件を取り出すと、次のように書けます。
M_{\mathrm{retrieved}} = {m_i \mid \mathrm{rank}(s_{q,i}) \le k}
この式自体は普通の retrieval に見えます。 しかし A-Mem では、取り出し対象の記憶がすでに構造化され、リンクされ、進化しています。
つまり、強いのは retrieval の式が特別だからではありません。 retrieval される前の記憶の作り方が違うのです。
図3:記憶をいくつ取り出すべきか
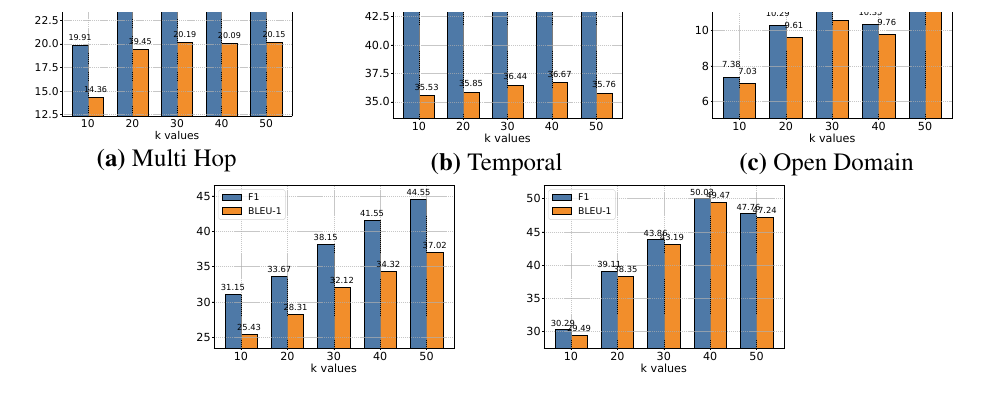
図3. retrieval で取り出す記憶数 (k) と性能の関係 出典: A-MEM: Agentic Memory for LLM Agents
この図は、質問時に取り出す記憶数 (k) を変えたとき、性能がどう変わるかを示しています。
ここで重要なのは、記憶は多く取り出せばよいわけではないことです。 取り出す記憶が少なすぎると、必要な情報が足りません。 一方で、多すぎると関係の薄い記憶も混ざり、かえってノイズになります。
これは、長期記憶を使うLLMアプリでかなり重要です。
思い出す量が少なすぎる → 情報不足
思い出す量が多すぎる → ノイズが増える
ちょうどよい量 → 文脈が補強される
ここでも、Lost in the Middle の話とつながります。 長いコンテキストに大量の記憶を入れれば、重要情報が埋もれる可能性があります。だからこそ、A-Mem のように記憶を事前に整理し、必要なものを適切な量だけ取り出す設計が重要になります。
WujiangXu/A-mem の README でも、retrieve_k はクエリごとに取り出す memory 数であり、モデルごとに調整することが案内されています。(GitHub)
図4・図5:記憶表現はどう整理されるのか
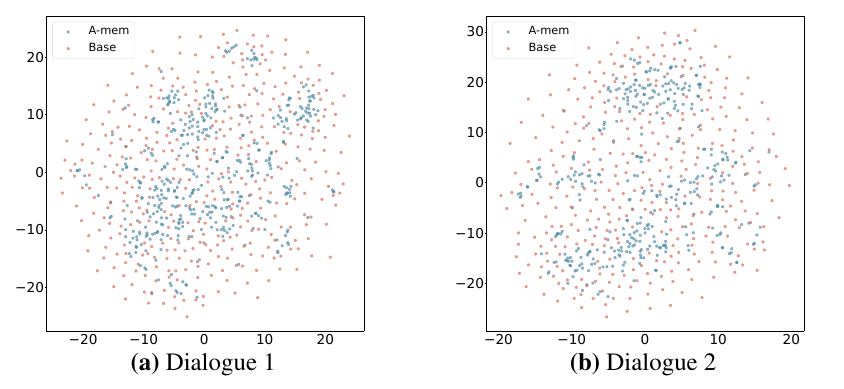
図4. A-Mem による memory embedding の可視化(Dialogue 1-2) 出典: A-MEM: Agentic Memory for LLM Agents
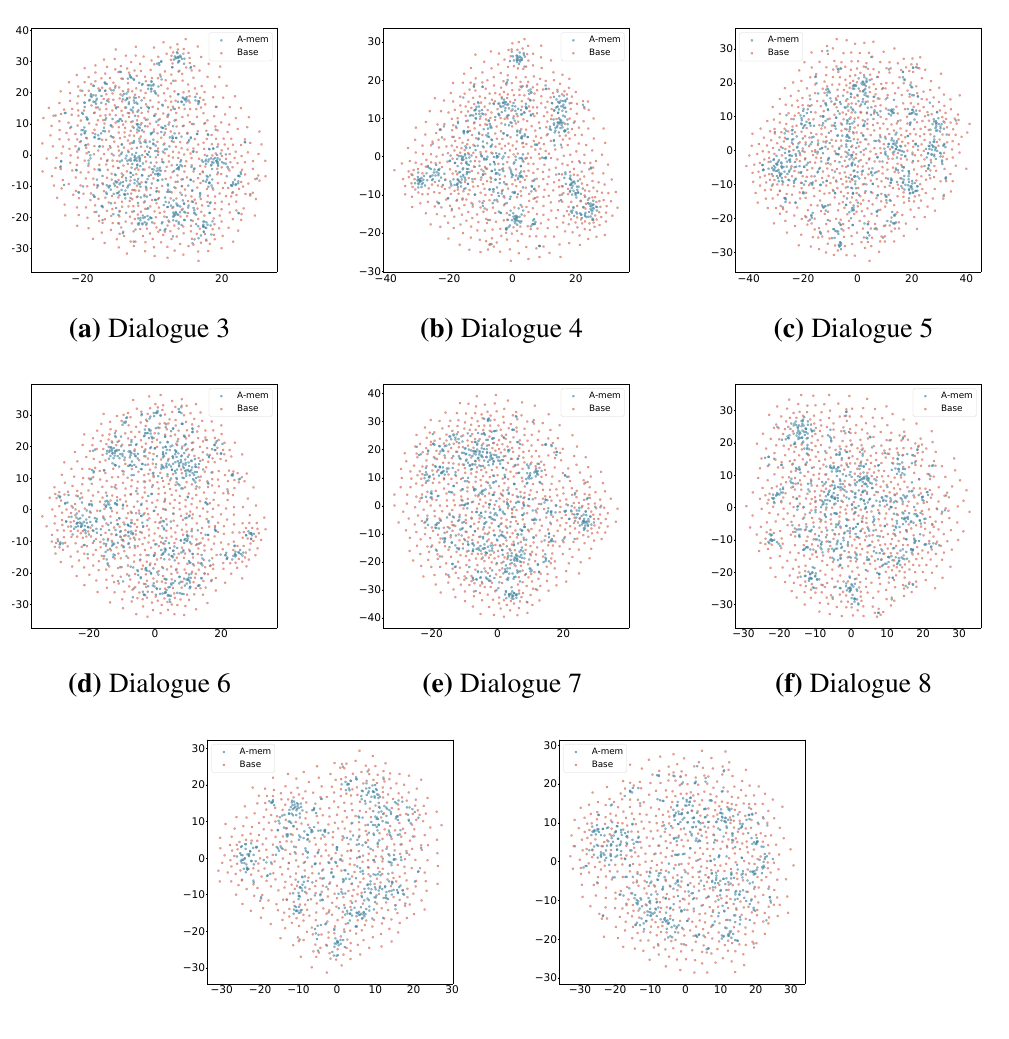
図5. 複数 dialogue における memory embedding の可視化 出典: A-MEM: Agentic Memory for LLM Agents
図4と図5は、A-Mem とベースラインの memory embedding を t-SNE で可視化した図です。
ここで見たいのは、A-Mem の記憶がよりまとまりを持った分布になっている点です。 これは、A-Mem が単にログを保存しているだけではなく、keywords、tags、context、links を使って、記憶を意味的に整理していることを視覚的に示す図として読めます。
もちろん、t-SNE はあくまで可視化なので、この図だけで性能が証明されるわけではありません。 ただ、A-Mem の主張である、
記憶は、ただ保存されるだけではなく、整理される
という点が、視覚的になんとなく伝わるものになっていると思っています
実装するとしたらどう作るか
A-Mem を完全に再現するには論文実装を読む必要がありますが、アプリ開発に応用するなら、まずは次のような設計が考えられます。
class MemoryNote:
id: str
content: str
timestamp: str
keywords: list[str]
tags: list[str]
context: str
linked_memory_ids: list[str]
embedding: list[float]
保存時の流れはこうです。
def add_memory(content: str):
# 1. LLMで記憶メタデータを生成
keywords, tags, context = llm_generate_metadata(content)
# 2. content + metadata から embedding を作る
embedding = encoder.embed(
content + " " + " ".join(keywords) + " " + " ".join(tags) + " " + context
)
# 3. vector DB に保存
note_id = save_note(content, keywords, tags, context, embedding)
# 4. 近い記憶を検索
related_notes = search_similar_notes(embedding, k=10)
# 5. 関連性を判定してリンクする
links = llm_judge_links(content, related_notes)
# 6. 必要なら古い記憶の context / tags を更新する
evolve_related_notes(note_id, related_notes, links)
return note_id
質問時の流れはこうです。
def retrieve_for_query(query: str):
query_embedding = encoder.embed(query)
notes = search_similar_notes(query_embedding, k=10)
return notes
A-mem-sys では、実際に AgenticMemorySystem を使って memory を追加し、LLM が自動的に keywords、context、tags を生成し、content と metadata を使って ChromaDB に保存する例が示されています。また、OpenAI、Ollama、OpenRouter、SGLang など複数の backend で初期化できる例も載っています。(GitHub)
ここで実装上かなり大事なのは、raw memory と derived memory を分けることになると思います。
raw memory:
ユーザーが実際に言ったこと
derived memory:
LLMが生成した tags / context / summary / links
これを分けないと、ユーザーが実際に言ったことと、LLM が解釈したことが混ざります。
A-Mem 的な設計は強力ですが、LLM の解釈が常に正しいとは限りません。 そのため、元のログは残しつつ、LLM が作った文脈説明は派生データとして扱っているようです。
どこに応用できるのか
A-Mem の考え方は、LLMを利用するシステムを開発する際に使用することができます・
1. 長期チャットアプリ
ユーザーの好み、説明スタイル、過去の質問傾向を、単なる履歴ではなく記憶ノートとして保存できます。
たとえば、
ユーザーは数式を使った説明を好む
ユーザーは専門用語を先に定義してほしい
ユーザーは論文解説で「次に読むべき論文」も知りたい
といった情報を、別々のログではなく関連した記憶として扱えます。
2. コーディングエージェント
プロジェクト固有のルール、設計判断、過去に失敗した実装、依存関係の癖などを記憶できます。
たとえば、
このプロジェクトでは Room の migration を明示的に書く
AGP 9.0 では Kotlin plugin の扱いに注意する
通知サービスでは foreground service type が必要
のような情報を、プロジェクト記憶として育てられます。
3. リサーチ支援
調査結果をまとめるたび、関連情報、結果、メリット、デメリットをノート化し、別の調査結果とリンクできます。
4. 複数エージェントの共有記憶
複数のエージェントが同じ記憶システムを参照する構成にも応用できます。
たとえば、
調査エージェント
実装エージェント
レビューエージェント
が同じ memory notes を参照すれば、プロジェクト全体の知識を共有できます。
注意点
A-Mem は魅力的ですが、実運用では注意点もあります。
1. LLM が作る context や tags は事実ではなく解釈です
LLM が生成した context は便利です。 ただし、それは元の発言そのものではありません。
たとえば、ユーザーが、
この説明は少し分かりにくいです
と言っただけなのに、LLM が、
ユーザーはこの分野に苦手意識がある
と解釈してしまうかもしれません。
これは危険です。 そのため、元ログと解釈ログは必ず分けた方がよいです。
2. Memory Evolution は便利ですが、決めつけも生みます
新しい記憶で古い記憶を更新できるのは強力です。 しかし、それは裏を返すと、古い記憶の意味が後から変わるということです。
たとえば、
ユーザーはPythonをよく使う
が、いつの間にか、
ユーザーは常にPythonを最優先する
になってしまうと困ります。
実装では、
元の記憶は消さない
更新履歴を残す
confidence を持たせる
ユーザーが編集・削除できるようにする
といった設計が必要です。
3. 取り出す記憶数は多ければよいわけではありません
長期記憶では、つい多くの記憶を取り出したくなります。 しかし、多すぎる記憶はノイズになります。
これは Lost in the Middle の問題ともつながります。 大事な記憶を入れても、長い文脈の中に埋もれてしまえば、モデルがうまく使えない可能性があります。
だからこそ、A-Mem のように、記憶を事前に整理し、関連性を付け、必要なものを適切な量だけ取り出す設計が重要になります。
まとめ
A-Mem は、LLMエージェントの長期記憶を考えるうえでかなり参考になる論文だと思いました。
この論文のポイントは、記憶をただ保存して検索するのではなく、
ノート化する
意味づけする
関連する記憶同士をリンクする
新しい記憶で古い記憶も更新する
必要な記憶だけ取り出す
という流れを作っていることだと思っています。
LLMアプリの記憶設計のアイディアとして A-Mem は、 「どれだけ長く覚えられるか」だけではなく、 「覚えた内容同士をどうつなげ、どう育てるか」 と提案した論文だと思います。