LLMのAPI使用料金は、入出力の公開価格だけでは比較できない
LLMのAPI料金を比較するとき、ふつうは「入力トークン単価」と「出力トークン単価」の公開価格表を見て、どのモデルが安いかを判断します。しかし、想定以上に実際の支払額はがかかる可能性があります。それがなぜかを説明する論文が、2024年4月に発表されました。タイトルはSpeech LLMs are Contextual Reasoning Transcribersです。
結論
LLM、とくに reasoning model のAPI料金は、公開されている入力単価・出力単価だけを見ても正しく比較できないです。なぜなら、実際の課金額は「見えている出力」だけでなく、モデルが内部で使う thinking token に強く左右されるからです。論文では、8個の推論モデルと9種類のタスクを比較した結果、モデルペア比較の 21.8% で「安いはずのモデルのほうが実際は高い」という価格逆転が起き、最大では28倍もの差が出ると報告しています。
つまり、この論文が言っているのはこうです。 「APIの公開価格表は、実運用コストの見積もり表としては信用しきれない」。 本当に知りたいのが「このモデルは実際にいくらかかるのか」なら、入出力単価だけでは不十分で、そのモデルがどれだけ内部で考え込むかまで見ないといけません。
まず、論文は何を調べたのか
この論文は、推論モデルの listed price と actual cost がどれくらいズレるのかを調べた研究です。対象は GPT-5.2, GPT-5 Mini, Gemini 3.1 Pro, Gemini 3 Flash, Claude Opus 4.6, Claude Haiku 4.5, Kimi K2.5, MiniMax-M2.5 の8モデルで、数学、科学QA、コード生成、知識QAなど9種類のタスクで比較しています。著者たちは、単なる価格表比較ではなく、実際にAPIを使ったときのトークン消費に基づいてコストを監査しています。
論文で置いている1クエリのコスト式は次です。
[ c_m(q)=p_n_(q)+p_n_(q) ]
ここで、
- (p_):入力トークン単価
- (p_):出力トークン単価
- (n_(q)):入力トークン数
- (n_(q)):出力トークン数
です。 一見すると普通の式ですが、重要なのは (n_(q)) の中に、ユーザに見える返答だけでなく、thinking token のような内部的な推論トークンが効いてくる点です。ここが、公開価格比較だけでは見抜けない部分です。
図1:この論文が言いたいことを一発で示す図
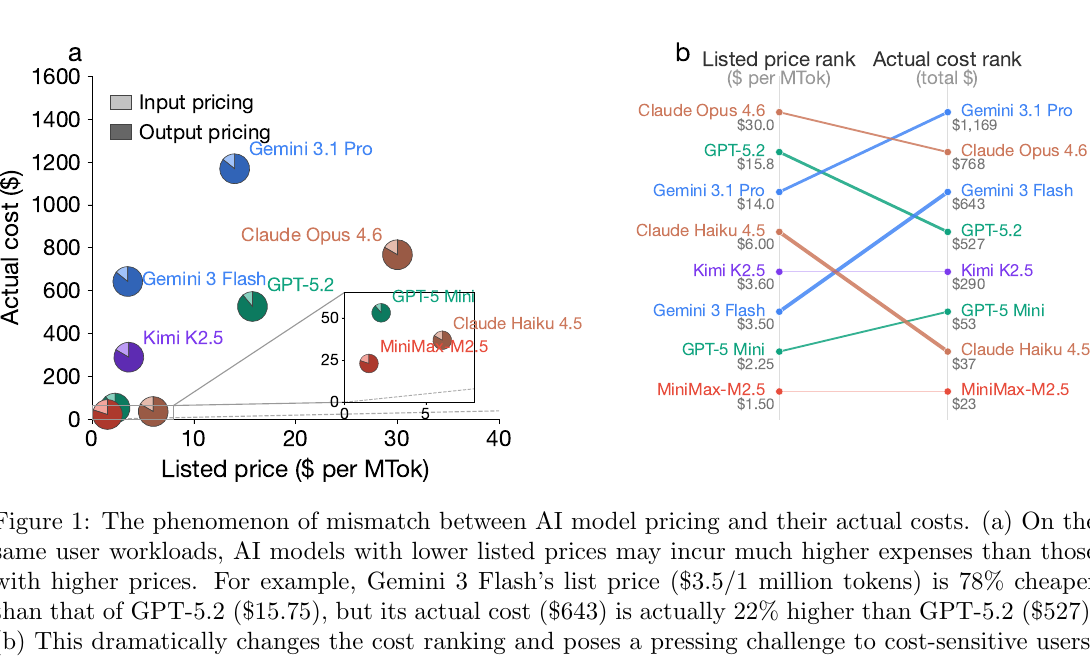
図1は、**「安い listed price のモデルが、同じタスクでは高くつく」**ことを、具体例で見せています。論文では、Gemini 3 Flash の listed price は GPT-5.2 より 78% 安いのに、実際の total cost は 22% 高いと示しています。さらに、価格順位と実コスト順位が入れ替わっており、価格表だけを見て“こちらが安い”と判断すると外すことがある、と分かります。
図2:しかも、このズレはたまたまではない
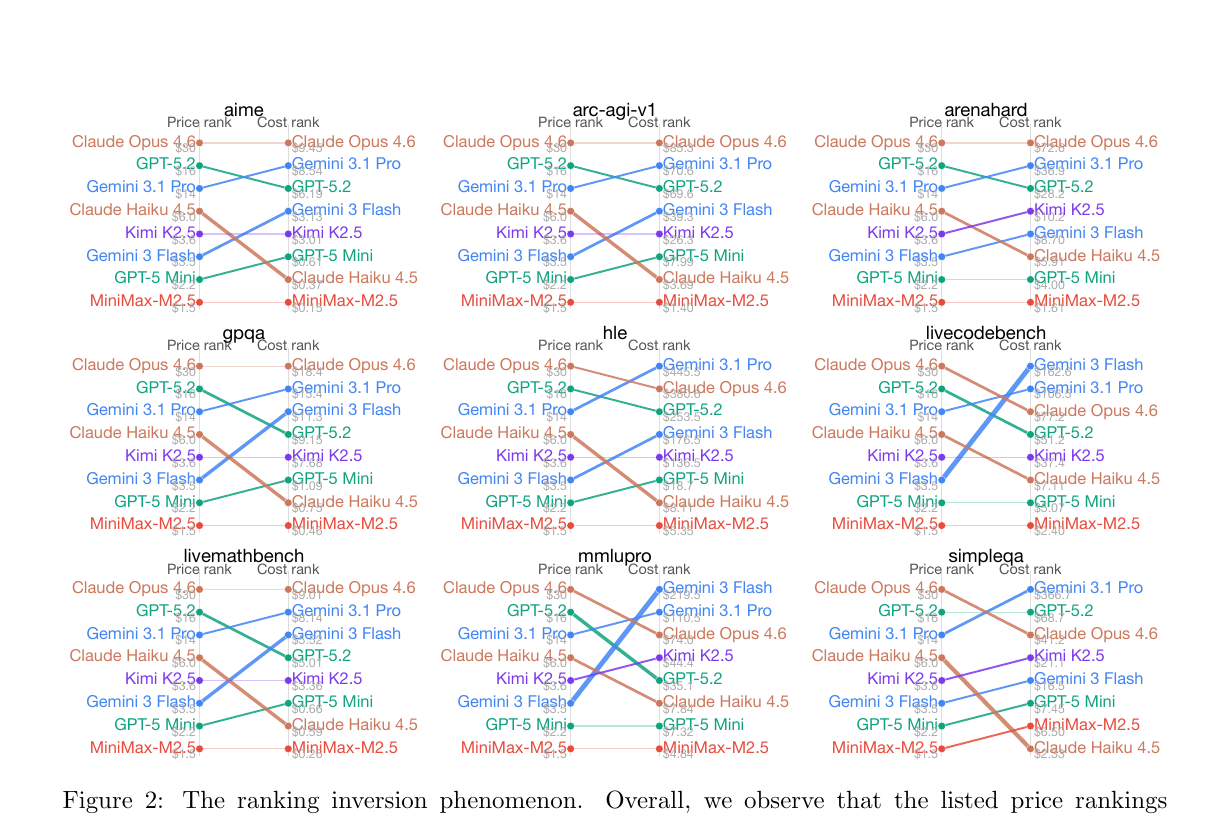
図2では、9種類のタスクごとに、listed price の順位とactual cost の順位が並べて描かれています。線が交差しているところほど、価格表ベースの順位が実コスト順位と食い違っています。論文では、全 252 個のモデルペア比較のうち 55比較、つまり 21.8% で価格逆転が起きたとまとめています。
しかも、この図でもう1つ重要なのは、モデルの安さがタスク依存だという点です。あるタスクでは安いモデルが、別のタスクでは高くなる。論文では、MiniMax-M2.5 が 9タスク中8タスクで最安ですが、SimpleQA では最安ではない、と説明されています。つまり、「このモデルは常に安い」とは言えないのです。公開価格表は固定でも、実コスト順位はタスクの種類で変わります。
図3:では、なぜズレるのか
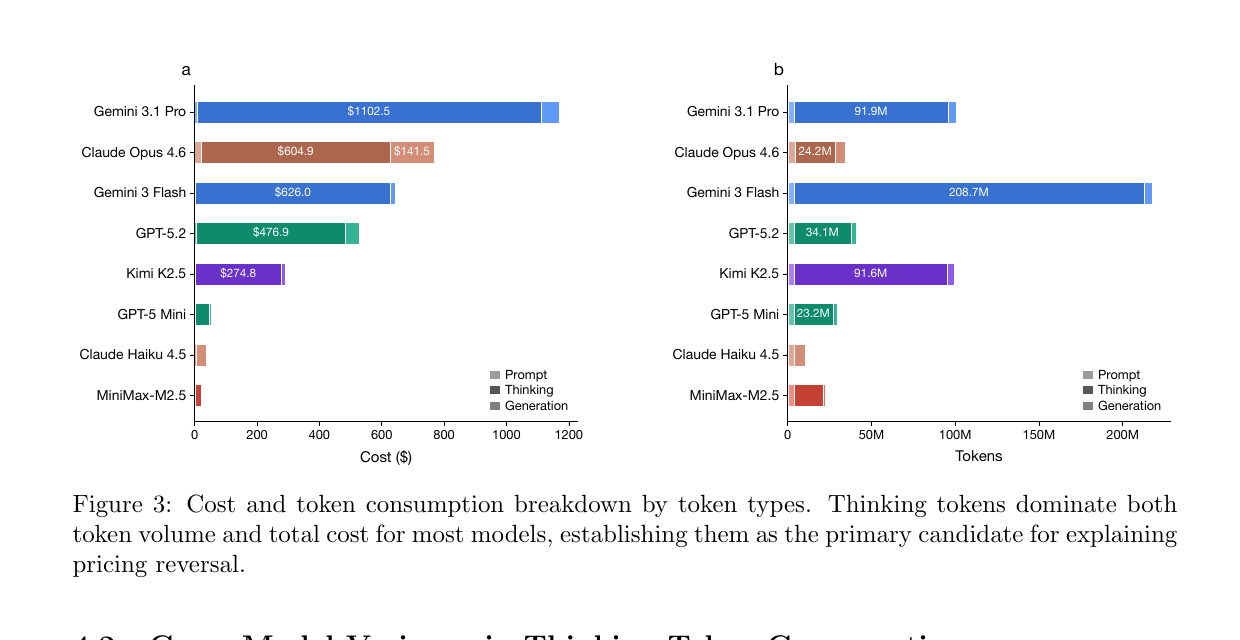
ここでで分かることトークン量を prompt / thinking / generation に分けて見せています。結論としては、thinking token がほとんどのモデルでコストの大部分を占める、ということです。つまり、価格がずれてしまう原因の候補は thinking token だと言っています。
この図で、左は「お金の内訳」、右は「トークン量の内訳」です。もし prompt や visible generation が主要因なら、公開価格比較でもそこそこ当たりそうです。ですが実際には、見えない thinking の山が大きい。だから、見えている返答が似た長さでも、実はその前に大量の内部推論をしていて、料金が膨らんでいます。
図4:同じ問題でも、モデルによって「考え込み方」が全然違う
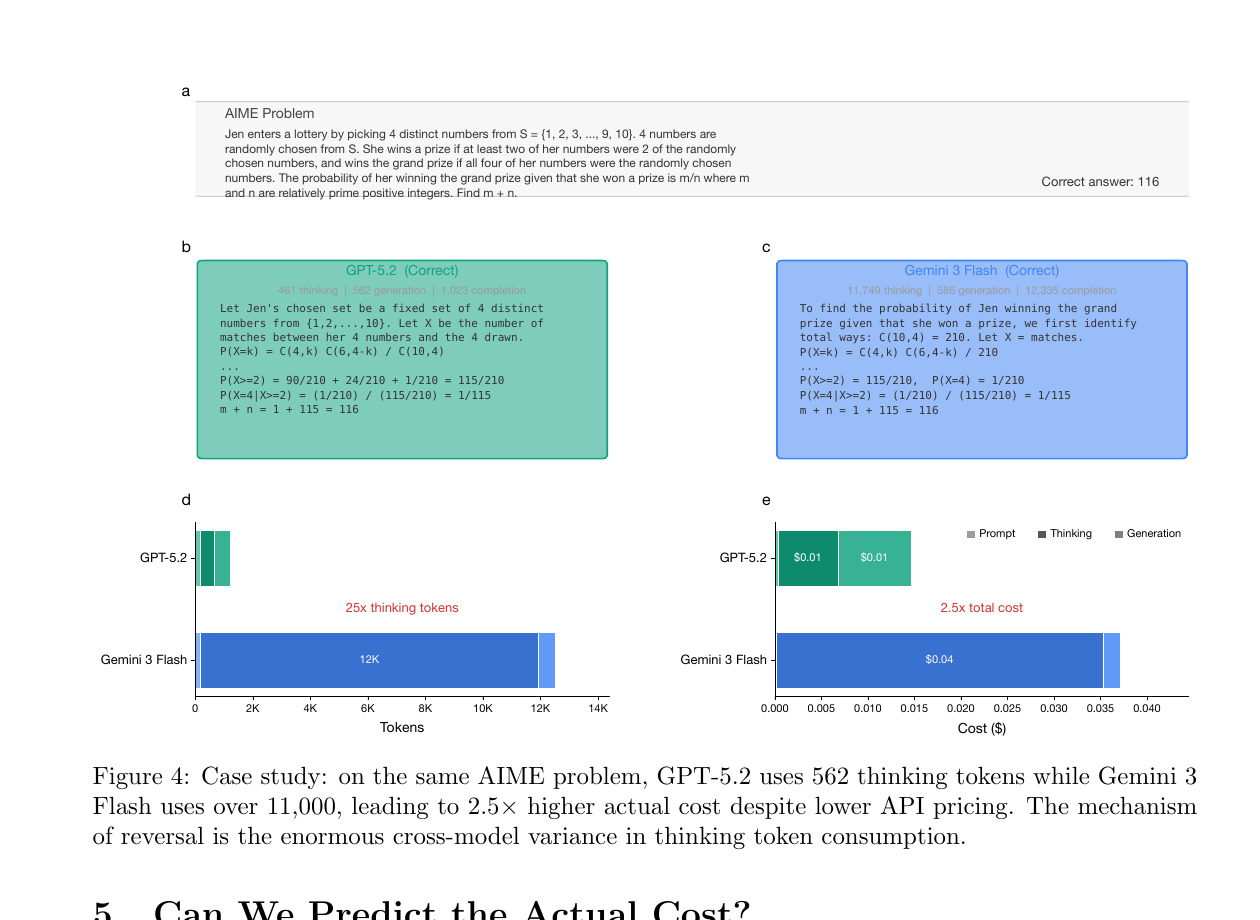
この図4は、AIMEの同じ1問を GPT-5.2 と Gemini 3 Flash に解かせた例です。どちらも正答にたどり着いていて、見える回答の雰囲気も大きくは違いません。ところが、thinking token は GPT-5.2 が 562、Gemini 3 Flash が 11,000超 で、約20倍の差があります。その結果、Gemini 3 Flash は単価が安いのに、この1問の実コストでは 2.5倍高いという結果になります。
図5:本当に原因は thinking token なのか
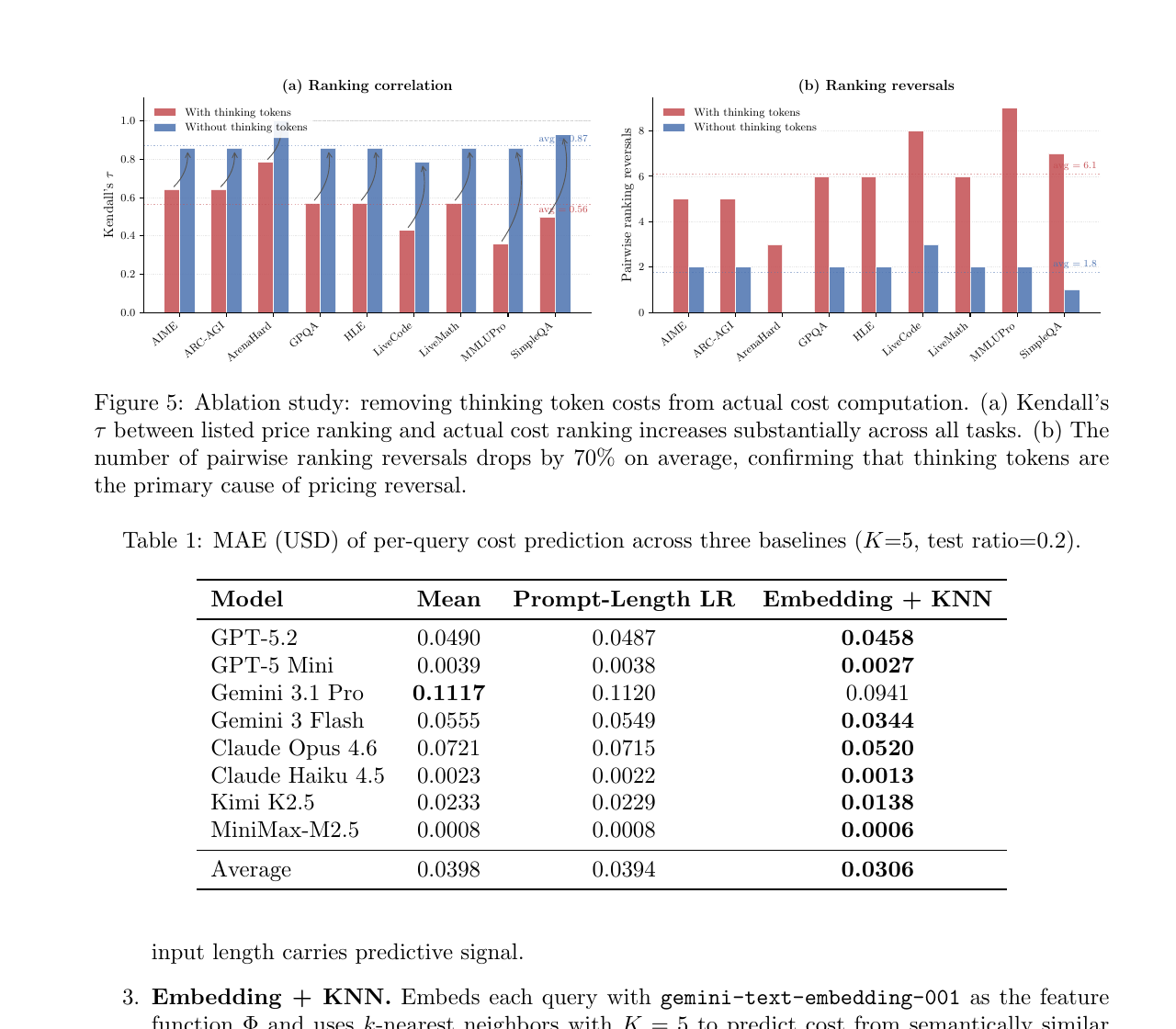
ここで著者たちは、検証をしています。 thinking token の課金だけをゼロにして、もう一度順位を計算するのです。もし thinking token が本当の原因なら、それを除いたときに、listed price の順位と実コスト順位はかなり揃うはずです。実際、その通りになりました。平均 Kendall’s (\tau) は 0.563 から 0.873 に上がり、ペア逆転数は 1タスク平均 6.1件 から 1.8件 に減っています。論文はこれをもって、thinking token が価格逆転の主因だと結論づけています。
この図は、因果の確認として重要です。 図3や図4だけだと、「thinking token が大きいのは分かった。でも本当にそれが原因なのか?」という疑問が残ります。図5はその疑問に対して、thinking を消すと逆転もかなり消えると示しています。
ここまでを一文で言うと
ここまでの図をまとめると、論文の主張はこうです。
LLMのAPI料金は、入力単価と出力単価の公開価格表だけでは比べられない。なぜなら、モデルごとの thinking token 消費量が大きく異なり、それが実コストをひっくり返すからである。
論文の後半:では、事前に実コストを予測できるのか
「ならば、問い合わせ前に実コストを予測すればよいのでは」と考え、コスト予測問題も扱います。著者たちは平均予測、prompt長による線形回帰、埋め込み + KNN というベースラインを試しますが、高分散モデルでは精度がよくありません。つまり、実コストは簡単には当てられないと示します。
さらに著者たちは、同じクエリを同じモデルに複数回投げても、内部 reasoning の揺れのせいでコストがかなり変動すると説明しています。つまり、「予測器が下手だから外れる」のではなく、そもそも同じ質問でもコスト自体が揺れるのです。だから実コスト予測は、本質的に難しい open challenge だと位置づけられています。
まとめ
この論文は、LLMのAPI料金を「入力単価と出力単価の公開価格表」だけで比べる危うさを示した研究である。8つの推論モデルと9種類のタスクを比較した結果、安いはずのモデルが実際には高くつく価格逆転が 21.8% のモデル比較で発生した。主因は、ユーザから見えない thinking token の大量消費であり、これを除くと価格順位と実コスト順位は大きく整合する。つまり、reasoning model のコストを本当に見積もりたいなら、公開価格の比較だけでは足りず、実ワークロードに対する token 消費の監査をすることが必要である。