LLMエージェントの長期記憶では、過去の会話をただ保存するだけでなく、質問に答えるために必要な記憶をうまく取り出す必要があります。HiGMemは、会話を「細かい発言」と「出来事のまとまり」に分け、LLMに読むべき発言だけを選ばせる長期記憶システムです。
参考にしたもの
-
HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents Shuqi Cao, Jingyi He, Fei Tan. arXiv:2604.18349。2026年4月20日投稿、2026年4月22日 v2。Findings of ACL 2026 accepted / camera-ready version。ライセンスはarXiv HTML上で CC BY 4.0 と表示されています。
-
ZeroLoss-Lab/HiGMem HiGMemの公式再現コード。確認日: 2026年5月1日。READMEでは、Turn / Event / optional Profile layers、LLM-guided memory construction、reasoning-aware retrieval、LoCoMo-10 reproduction、OpenAI-compatible backend対応が説明されています。
-
A-MEM: Agentic Memory for LLM Agents Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, Yongfeng Zhang. arXiv:2502.12110。2025年2月17日投稿。Zettelkastenの考え方をLLMエージェントの記憶管理に応用し、dynamic indexing、linking、memory evolutionを行う記憶システムを提案しています。
-
Lost in the Middle: How Language Models Use Long Contexts Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. arXiv:2307.03172。2023年7月6日投稿。長いコンテキストの中で、重要情報が先頭や末尾にある場合に比べ、中間にある場合は性能が落ちやすいことを示した論文です。
-
Evaluating Very Long-Term Conversational Memory of LLM Agents Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, Yuwei Fang. arXiv:2402.17753。2024年2月27日投稿。LoCoMoという長期会話メモリ評価用ベンチマークを提案した論文です。
Contents
- 結論
- まず、何が問題なのか
- A-Memで解けたこと、まだ残ること
- HiGMemとは何か
- 図1:HiGMemの全体構造
- Turn node と Event node
- 数式でみるHiGMem
- 図2:普通のベクトル検索とHiGMemの違い
- 実験結果:少ないTurnで近いRecallを保つ
- コスト面では何が起きるのか
- 実装リンクから見るHiGMem
- ZettelkastenとHiGMemはどうつながるのか
- LLMチャットアプリに応用するとどうなるか
- 注意点
- まとめ
結論
HiGMemは、LLMエージェントの長期記憶を「たくさん思い出す」方向から、「読むべき証拠だけを選ぶ」方向へ進める論文です。
LLMエージェントに長期記憶を持たせると、過去の会話や経験を保存し、質問時にそれを取り出して回答に使うことになります。
しかし、ここで問題があります。
関係ありそうな記憶を多く取れば、必要な情報を取り逃がしにくくなります。 一方で、不要な記憶も増えます。
すると、回答LLMに渡すコンテキストが大きくなり、コストが増え、余計な情報に引っ張られやすくなります。
HiGMemはこの問題に対して、会話記憶を次の2階層で整理します。
Event Layer:
出来事のまとまり、話題、要約、fact sheet
Turn Layer:
実際の細かい発言、対話ターン、メタデータ
質問が来たとき、HiGMemはまずEvent summaryを見ます。 そして、そのEventにぶら下がっているTurnの中から、LLMが「この質問に答えるために読むべきTurn」を選びます。
つまり、HiGMemはこういう仕組みです。
過去会話を全部読む
ではなく、
出来事の見出しを見る
↓
関係ありそうな出来事を選ぶ
↓
その中の必要な発言だけ読む
この違いによって、HiGMemはLoCoMo10でA-Memよりかなり少ないTurn数を回答LLMに渡しながら、近いRecallを保ち、Precisionを大きく改善しています。
まず、何が問題なのか
LLMエージェントやチャットアプリを作っていると、「過去の会話をどう覚えさせるか」という問題にぶつかります。
一番単純なのは、過去ログをそのままプロンプトに入れる方法です。
過去ログ
+
現在の質問
↓
LLM
↓
回答
しかし、これはすぐに苦しくなります。
まず、トークン数が増えます。 料金も増えます。 応答も遅くなります。
ただし、それ以上に重要なのは、長い入力を与えたからといって、LLMがその中の情報を安定して使えるとは限らないことです。
この点を示した代表的な論文が、Lost in the Middleです。 この論文では、関連情報が入力の最初や最後にある場合は比較的使われやすい一方で、長いコンテキストの中間にある場合は性能が落ちやすいことが報告されています。
つまり、
全部入れれば大丈夫
ではありません。
むしろ、
全部入れたせいで、大事な情報が埋もれる
可能性があります。
そこで次に考えられるのが、embedding検索です。
過去ログを保存する
↓
embeddingを作る
↓
質問に近いログを検索する
↓
上位K件をLLMに渡す
これはかなり有効です。
しかし、会話履歴が長くなると、別の問題が出ます。
それは、質問に「似ている」記憶と、答えに「必要な」記憶が同じとは限らないことです。
たとえば、ユーザーが過去に「新しいスポーツカーを買った」と話していたとします。 後から「どんな車に乗っているのか」と聞かれたとき、本当に必要なのは「スポーツカーを買った」という発言です。
しかし、単純なベクトル検索では、drive、car、vehicleのような語に反応して、旅行や移動の話まで拾ってしまうかもしれません。
ここで必要なのは、単に「似ている記憶」を取ることではありません。 「この質問に答えるために読む価値がある記憶」を選ぶことです。
HiGMemは、この問題に対する提案です。
A-Memで解けたこと、まだ残ること
以前の記事では、A-Memを扱いました。
A-Memを読む:LLMエージェントに「育つ記憶」を持たせる長期記憶設計
A-Memの大きな特徴は、記憶をただの過去ログとして保存しないことです。
A-Memでは、会話や経験を「記憶ノート」として保存します。 さらに、その記憶ノートにkeywords、tags、contextを付け、関連する記憶同士にリンクを張り、新しい記憶によって古い記憶の文脈も更新します。
A-Memはこのような設計です。
過去ログ
↓
記憶ノート化
↓
関連記憶とリンク
↓
新しい記憶で古い記憶も更新
↓
育っていく記憶ネットワーク
これは、Zettelkastenに近い考え方です。
Zettelkastenでは、1つのノートに1つの考えを書き、それらをリンクして知識ネットワークとして育てます。 A-Memは、この考え方をLLMエージェントの記憶に応用しています。
ただし、記憶をうまく保存できても、次の問題が残ります。
それは、
質問時に、どの記憶をLLMに渡すべきか
です。
記憶が増えれば増えるほど、検索で取れる候補も増えます。
必要な情報を取り逃がしたくないので、多めに取る。 すると不要な記憶も増える。 その結果、回答LLMに渡すコンテキストが膨らむ。
この問題を、HiGMemは正面から扱います。
HiGMemとは何か
HiGMemの正式名称は、 HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents です。
日本語にすると、 長期対話エージェントのための階層型かつLLM誘導型メモリシステム になります。
名前の中にある重要語は2つです。
Hierarchical:
記憶を階層化する
LLM-Guided:
LLMに検索・選別を手伝わせる
HiGMemは、長期会話の記憶を次の2階層で扱います。
Event node:
複数のTurnをまとめた出来事
Turn node:
実際の細かい会話ターン
この2階層が、HiGMemの中心です。
たとえば、会話にこういう発言があったとします。
Evan: I bought a new Prius last month.
Evan: I usually drive it to work.
Evan: The fuel efficiency is great.
これらの発言は、それぞれTurn nodeになります。
一方で、上位には次のようなEvent nodeができます。
Event:
Evan talked about buying and using his new Prius.
Linked Turns:
- bought a new Prius
- drives it to work
- likes the fuel efficiency
質問が、
What kind of car does Evan drive?
なら、HiGMemはEvent summaryを見て、
Evanの車についてのEventがある
↓
そのEventの下にあるTurnを読めば答えがありそう
と判断できます。
ここで重要なのは、HiGMemがいきなり細かいTurnを全部探しに行くのではなく、まずEventという大きなまとまりを見ることです。
図1:HiGMemの全体構造
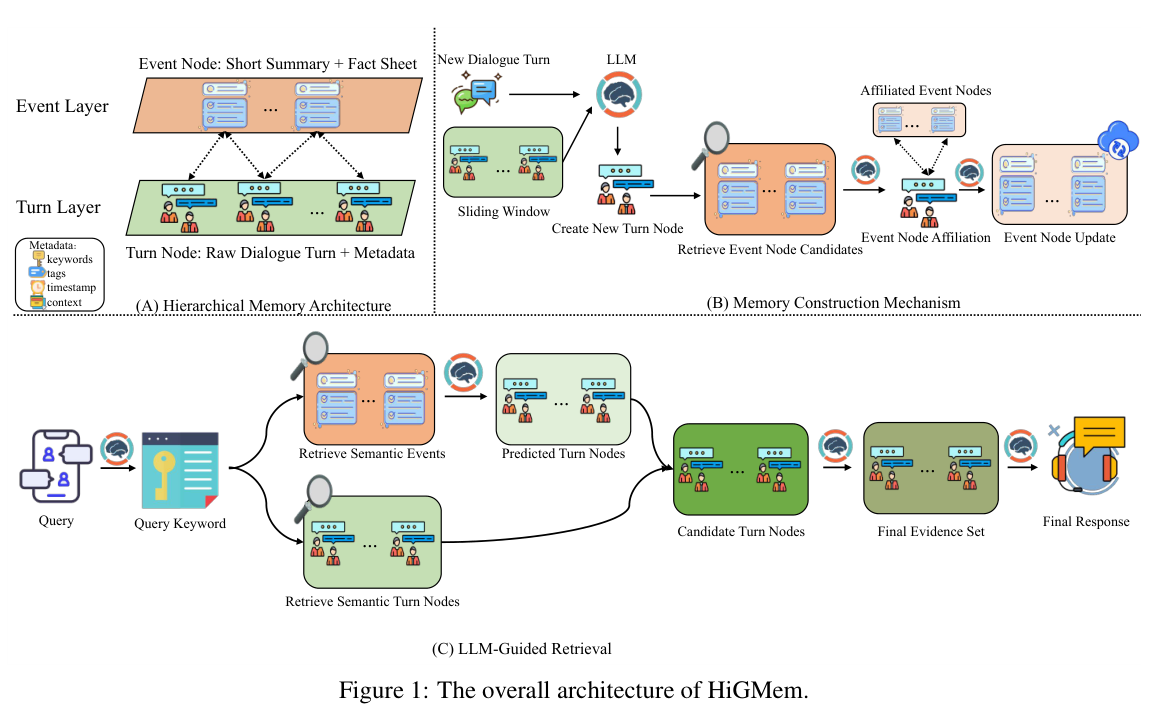
図1. HiGMemの全体アーキテクチャ 出典: Cao et al., “HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents”, Figure 1. ライセンス: CC BY 4.0.
図1を見ると、HiGMemの全体像がかなり分かりやすくなります。
この図は、大きく3つに分かれています。
A. Hierarchical Memory Architecture
B. Memory Construction Mechanism
C. LLM-Guided Retrieval
まず左側では、記憶がTurn LayerとEvent Layerに分かれています。
Turn Layerには、実際の発言とメタデータが保存されます。 Event Layerには、複数のTurnをまとめたEvent summaryやfact sheetが保存されます。
中央では、新しい会話Turnが入ったときの処理が描かれています。
新しい会話Turn
↓
LLMがmetadataを作る
↓
Turn nodeを作る
↓
関連するEvent候補を探す
↓
LLMがEvent所属を判断する
↓
Event summaryやfact sheetを更新する
右側では、質問時の検索処理が描かれています。
質問
↓
Query keywordを作る
↓
Turnを検索する
↓
Eventも検索する
↓
Eventに紐づくTurnの中からLLMが読むべきものを選ぶ
↓
最終Evidence setを作る
↓
回答LLMに渡す
この図で見るべきポイントは、HiGMemが単に「ベクトル検索を2回する仕組み」ではないことです。
HiGMemは、Event summaryを使って、LLMに「この質問に答えるために読むべきTurnはどれか」を判断させます。
つまり、検索を「似ているものを取る処理」から、「答えに使う証拠を選ぶ処理」に近づけています。
Turn node と Event node
HiGMemでは、Turn nodeとEvent nodeが重要です。
Turn node
Turn nodeは、会話の細かい発言単位です。
ただし、生の発言だけではありません。 LLMが生成したメタデータも持ちます。
Turn node:
- raw dialogue turn
- keywords
- tags
- timestamp
- context
たとえば、
Evan: I bought a new Prius last month.
という発言があったとします。
これをTurn nodeにすると、次のようなイメージになります。
{
"speaker": "Evan",
"content": "I bought a new Prius last month.",
"keywords": ["Evan", "Prius", "car", "bought"],
"tags": ["vehicle", "personal_fact"],
"timestamp": "session_03",
"context": "Evan talked about buying a new car."
}
Event node
Event nodeは、複数のTurnをまとめた出来事単位です。
Event node:
- short summary
- fact sheet
- linked Turn ids
たとえば、複数のTurnから次のEventができます。
{
"title": "Evan's new car",
"summary": "Evan discussed buying and using his new Prius.",
"fact_sheet": {
"person": "Evan",
"vehicle": "Prius",
"usage": "drives it to work"
},
"turn_ids": ["turn_104", "turn_108", "turn_112"]
}
Turn nodeは、細かい証拠です。 Event nodeは、その証拠を探すための見出しです。
この2つを分けることで、HiGMemはまず大きな意味のまとまりを見て、そのあと細かい発言を読みにいけます。
数式でみるHiGMem
HiGMemの仕組みは、数式で見るとかなり分かりやすくなります。
ここでは、論文中の式を3つの段階に分けて見ます。
1. Turn nodeを作る
新しい対話ターンを D_t とします。
HiGMemは、その発言だけを見るのではなく、直近の会話文脈も見ます。
W_t = {T_{t-m}, ..., T_{t-1}}
論文では、実験時のスライディングウィンドウサイズは m = 5 です。
つまり、新しい発言を理解するときに、直前5Turnを文脈として使います。
そして、LLMがメタデータを作ります。
D_t -> LLM(. | W_t) -> M_t
ここで、M_t はkeywords、tags、timestamp、contextのようなメタデータです。
そしてTurn nodeは次のように表されます。
T_t = (D_t, M_t)
これは、
Turn node = 生の発言 + LLMが作ったメタデータ
という意味です。
生の発言だけでは検索しにくい場合でも、LLMが文脈を見てmetadataを付けることで、後から探しやすくなります。
2. TurnをEventに所属させる
次に、新しいTurn nodeをどのEvent nodeに所属させるかを決めます。
まず、新しいTurnのembeddingを e_t、既存Event nodeのembeddingを e_Ej とします。
類似度はコサイン類似度で計算します。
s_{t,j} = dot(e_t, e_Ej) / (||e_t|| ||e_Ej||)
これは、
新しいTurnと既存Eventがどれくらい意味的に近いか
を見る式です。
ただし、HiGMemはここで終わりません。
ベクトル検索で候補Eventを出したあと、LLMが最終的に所属先を判断します。
E* = f_affiliate(T_t | E_cand)
これは、
候補EventをLLMに見せる
↓
このTurnは既存Eventに入るべきか
↓
それとも新しいEventを作るべきか
↓
LLMが判断する
という意味です。
つまり、HiGMemでは、embeddingは候補を出す係です。 最終判断はLLMが行います。
3. Eventから読むべきTurnを選ぶ
質問を Q とします。
HiGMemは、まず質問から検索用キーワードを作ります。
q_kw = LLM(Q)
そのうえで、Turn layerから直接関連Turnを検索します。
T_semantic:
質問に意味的に近いTurn
同時に、Event layerから関連Eventも検索します。
E_semantic:
質問に意味的に近いEvent
ここからがHiGMemの一番重要な部分です。
検索されたEventには、関連Turnがぶら下がっています。 HiGMemは、そのEventに紐づくTurnの中から、LLMに「読むべきTurn」を予測させます。
T_pred = union over E in E_semantic of Predict(T_E | Q, E)
これは、
検索されたEventごとに、
そのEventに含まれるTurn集合を見て、
質問に役立ちそうなTurnをLLMが選ぶ
という意味です。
その後、直接検索で取れたTurnと、Event経由で選ばれたTurnを合わせます。
T_cand = T_semantic union T_pred
最後に、LLMでフィルタして最終的な証拠集合を作ります。
T_final = Filter(T_cand | Q)
この T_final だけが、回答LLMに渡されます。
つまり、HiGMemはこういう流れです。
Turnを直接探す
+
Eventから読むべきTurnを予測する
↓
候補Turnを統合する
↓
LLMでさらに絞る
↓
少数の証拠Turnだけ回答LLMへ渡す
図2:普通のベクトル検索とHiGMemの違い

図2. Passive Vector RetrievalとLLM-Guided Retrievalの違い 出典: Cao et al., “HiGMem: A Hierarchical and LLM-Guided Memory System for Long-Term Conversational Agents”, Figure 2. ライセンス: CC BY 4.0.
図2では、普通のベクトル検索とHiGMemの違いが、かなり直感的に説明されています。
例として、次の質問が出てきます。
What kind of car does Evan drive?
普通のベクトル検索では、質問がkeywordsに分解されます。
kind
car
Evan
drive
すると、"drive" に引っ張られて、次のような記憶も取れてしまいます。
a two-hour drive
drive to the city
driving was tiring
これらは意味的には近いかもしれません。 しかし、質問に答える証拠ではありません。
本当に必要なのは、
my new Prius
のような発言です。
HiGMemでは、LLMが質問の意図を見ます。
Evanが運転している車種を知りたい
そして、Event summaryを手がかりに、Evanの車に関するEventを探します。 そのEventにぶら下がるTurnを見て、答えに必要なTurnを選びます。
ここで大事なのは、次の違いです。
ベクトル検索:
似ている記憶を探す
HiGMem:
答えに使える記憶を探す
もちろんHiGMemもembedding検索を使います。 しかし、embedding検索だけで終わらせず、Event summaryを使ってLLMが読むべきTurnを判断するところが違います。
実験結果:少ないTurnで近いRecallを保つ
HiGMemは、LoCoMo10で評価されています。
LoCoMo10は、長期会話メモリを評価するためのデータです。 論文では、LoCoMo10はLoCoMoから選ばれた10個の長い会話で、平均587 turns per conversationだと説明されています。
評価カテゴリは次の5つです。
Single-Hop:
1つの記憶で答えられる質問
Multi-Hop:
複数の記憶をつなぐ質問
Temporal:
時間・順序・日付に関する質問
Open-Domain:
より自由な質問
Adversarial:
ひっかけ・妨害候補を含む質問
F1スコア
論文のTable 1では、HiGMemは5カテゴリ中4カテゴリで最高F1を出しています。
| Method | Multi-Hop | Temporal | Open-Domain | Single-Hop | Adversarial |
|---|---|---|---|---|---|
| Base LLM | 0.25 | 0.39 | 0.12 | 0.44 | 0.30 |
| ReadAgent | 0.09 | 0.13 | 0.05 | 0.10 | 0.10 |
| MemoryBank | 0.05 | 0.10 | 0.06 | 0.07 | 0.07 |
| A-Mem | 0.27 | 0.39 | 0.10 | 0.42 | 0.54 |
| HiGMem | 0.31 | 0.34 | 0.15 | 0.49 | 0.78 |
特に大きいのはAdversarialです。
A-Mem:
0.54
HiGMem:
0.78
Adversarial質問では、余計な記憶や紛らわしい記憶が混ざると間違いやすくなります。
HiGMemは、回答LLMに渡す証拠Turnを絞るため、紛らわしい情報に引っ張られにくくなったと考えられます。
一方で、TemporalはA-Memの方が高いです。
A-Mem:
0.39
HiGMem:
0.34
これは重要な弱点です。
Event summaryで意味をまとめると、細かい時系列情報が少し丸められる可能性があります。
検索品質
HiGMemの強さが一番わかりやすいのは、Table 2です。
| Method | Avg K | Precision@K | Recall@K |
|---|---|---|---|
| A-Mem | 99.84 | 0.0101 | 0.7502 |
| HiGMem | 8.09 | 0.1909 | 0.7241 |
ここでAvg Kは、回答LLMに渡した平均Turn数です。
A-Memは平均99.84Turnを渡しています。 HiGMemは平均8.09Turnだけです。
それでもRecall@Kはかなり近いです。
A-Mem:
0.7502
HiGMem:
0.7241
一方で、Precision@Kは大きく改善しています。
A-Mem:
0.0101
HiGMem:
0.1909
つまり、HiGMemはこういうことを実現しています。
A-Mem:
たくさん渡して、必要な証拠を拾う
HiGMem:
少なく渡して、必要な証拠をかなり拾う
この論文の主張は、ほぼこの表に凝縮されています。
HiGMemは、記憶を多く思い出すのではなく、読むべき証拠を絞る方向へ進んでいます。
コスト面では何が起きるのか
HiGMemは、回答LLMに渡すTurnを減らします。
そのため、高価な回答モデルを使う場合、最終回答段階のトークンコストを大きく減らせます。
論文では、次のようなハイブリッド構成でコストを比較しています。
メモリ構築・検索:
GPT-4o-mini
最終回答:
GPT-5
Table 3では、次のような結果が報告されています。
| Cost Component | A-Mem | HiGMem |
|---|---|---|
| GPT-4o-mini Tokens | 11.81M | 54.35M |
| GPT-5 Answer Tokens | 25.38M | 1.62M |
| GPT-4o-mini Cost | $1.44 | $5.30 |
| GPT-5 Cost | $15.99 | $1.12 |
| Total Cost | $17.43 | $6.43 |
ここで面白いのは、HiGMemは前段のコストは増えていることです。
Event所属、Event更新、検索時フィルタなどでLLMを使うため、GPT-4o-mini側のトークンは増えます。
しかし、最終回答に渡すTurnが大きく減るため、高価なGPT-5側のトークンが大幅に減ります。
つまり、HiGMemはこういう分業をしています。
安いモデル:
記憶整理
Event分類
証拠選別
高いモデル:
最終回答
この考え方は、実際のLLMアプリ設計でもかなり使えそうです。
ただし、速くなるわけではありません。
論文のTable 4では、HiGMemはA-Memよりメモリ構築・質問応答の平均時間が長くなっています。
| Time Metric | A-Mem | HiGMem |
|---|---|---|
| Memory Construction | 6.38s | 15.59s |
| Question Answering | 5.91s | 9.42s |
つまり、HiGMemは、
回答LLMに渡す文脈:
減る
最終回答モデルのコスト:
減る
中間処理:
増える
レイテンシ:
増える可能性がある
というトレードオフです。
実装リンクから見るHiGMem
HiGMemは、公式再現コードがGitHubで公開されています。
READMEでは、HiGMemの特徴として次の内容が説明されています。
Hierarchical memory:
長い会話をTurn、Event、任意のProfile層に整理する
LLM-guided memory construction:
会話を読みながら構造化されたEvent memoryを増分構築する
Reasoning-aware retrieval:
candidate events and turnsを取得し、LLM judgmentsでevidenceをフィルタする
LoCoMo reproduction:
論文実験で使うLoCoMo-10 splitを含む
OpenAI-compatible backend:
OpenAI APIやvLLMのようなローカルOpenAI互換サービスを使える
実装の中心になりそうなファイルは次のあたりです。
run_fphm_evaluation.py:
メイン評価スクリプト
fphm_core.py:
HiGMemのメモリ構築・検索コア
memory_layer.py:
LLMとembedding backendまわり
prompts.py:
プロンプトテンプレート
data/locomo10.json:
LoCoMo-10再現用データ
oracle_test.py:
Oracle evidence baseline
full_context_test.py:
Full-context baseline
analyze_recall.py:
検索分析
READMEには、HiGMemが各会話Turnを次の順に処理すると説明されています。
1. Turn construction
2. Event affiliation
3. Event update
4. Retrieval for QA
5. Final answer generation
つまり、論文の流れと実装の流れがかなり対応しています。
再現コマンド
READMEには、単一サンプル実行の例として次のようなコマンドが示されています。
python run_fphm_evaluation.py \
--model gpt-4o-mini \
--backend openai \
--ablation-no-profile \
--ablation-event-metadata-only \
--ablation-no-link \
--k_event 10 \
--sample_index 0
また、OpenAI-compatible backendに対応しているため、vLLMなどを使ってローカルLLMで試す余地もあります。
現時点で、HiGMemを組み込んだ大規模な実用プロダクトが広く公開されているとは言いにくいです。
ただし、公式リポジトリにはLoCoMo10での再現コード、OpenAI-compatible backend、ローカルOpenAI互換サーバー向けの実行例が含まれているため、自分のLLMチャットアプリやローカルLLMエージェントに移植する土台としてはかなり参考になります。
ZettelkastenとHiGMemはどうつながるのか
A-Memでは、Zettelkastenの考え方が重要でした。
Zettelkastenは、1つのノートに1つの考えを書き、それらをリンクして知識ネットワークとして育てていくノート術です。
A-Memは、この発想をLLMエージェントの記憶に応用しました。
A-Mem:
記憶をノート化する
記憶同士をリンクする
新しい記憶で古い記憶も更新する
これは、記憶をどう育てるかの設計です。
一方、HiGMemは少し違う問題を見ています。
それは、
育った記憶の中から、何を読むべきか
です。
Zettelkasten的に記憶が増えていくと、ノートの数もリンクの数も増えます。
すると、次に問題になるのは、質問時にどのノートを読むべきかです。
HiGMemのEvent nodeは、Zettelkastenでいうと「関連ノート群についた小さな見出し」や「話題ごとの索引」に近い役割を持ちます。
A-Mem:
ノート同士をつなげて育てる
HiGMem:
出来事の見出しを作り、そこから読むべき発言を選ぶ
このように考えると、A-MemとHiGMemは対立するものではありません。
むしろ、次のように組み合わせられます。
A-Mem的な要素:
記憶ノートを作る
記憶同士をリンクする
記憶を進化させる
HiGMem的な要素:
TurnをEventにまとめる
Event summaryを作る
質問時にEventから読むべきTurnを選ぶ
つまり、
A-Mem:
記憶を育てる
HiGMem:
育った記憶から必要な証拠を選ぶ
という関係で見ると分かりやすいです。
LLMチャットアプリに応用するとどうなるか
HiGMemをLLMチャットアプリに入れるなら、まずは次のような設計が考えられます。
保存時
ユーザーの発言が入ったら、まずTurnとして保存します。
ユーザー発言
↓
Turnとして保存
- speaker
- content
- timestamp
- keywords
- tags
- context
- embedding
↓
既存Eventを検索
↓
LLMがEvent所属を判断
↓
既存Eventに追加 or 新Event作成
↓
Event summary / fact sheet / linked_turn_ids を更新
DBは、最小ならこうなります。
turns
id
speaker
content
timestamp
keywords_json
tags_json
context
embedding
events
id
title
summary
fact_sheet_json
keywords_json
tags_json
embedding
event_turn_links
event_id
turn_id
A-Mem的なリンクも足すなら、次のようなテーブルを追加できます。
memory_links
source_turn_id
target_turn_id
relation
confidence
この場合、A-Mem的な「記憶同士のリンク」と、HiGMem的な「Event-Turn階層」を両方使えます。
質問時
質問が来たときは、次のように処理します。
質問
↓
LLMで検索クエリへ変換
↓
Turn検索
↓
Event検索
↓
Eventごとに読むべきTurnをLLMが選ぶ
↓
候補Turnを統合
↓
LLMで最終フィルタ
↓
回答LLMへ渡す
擬似コードにすると、こうです。
def retrieve_memory(query: str):
# 1. 質問を検索向けに変換
query_keywords = llm_rewrite_query(query)
# 2. Turnを直接検索
semantic_turns = vector_search_turns(query_keywords, k=10)
# 3. Eventを検索
semantic_events = vector_search_events(query_keywords, k=10)
# 4. Eventの中から読むべきTurnをLLMで選ぶ
predicted_turns = []
for event in semantic_events:
linked_turns = load_turns(event.turn_ids)
selected_turns = llm_select_turns_from_event(
query=query,
event_summary=event.summary,
turns=linked_turns
)
predicted_turns.extend(selected_turns)
# 5. 候補を統合する
candidates = merge_unique(semantic_turns, predicted_turns)
# 6. 最終フィルタ
final_evidence = llm_filter_evidence(
query=query,
candidates=candidates
)
return final_evidence
この設計が効くのは、たとえば次のようなアプリです。
長期チャットアプリ:
ユーザーの好み、説明スタイル、過去の相談を覚える
コーディングエージェント:
プロジェクト固有の設計判断、過去のバグ、依存関係の癖を覚える
リサーチ支援:
読んだ論文、比較した手法、実験結果、次に読むべき論文を整理する
個人用ナレッジベース:
日々のメモや調査ログをEvent単位でまとめる
特に、長期チャットアプリでは、次のような問いに強くなりそうです。
前にAndroidアプリの通知まわりで何を直す話をした?
前に読んだA-Memの論文では何が重要だった?
Kaggleで試した最適化は何だった?
このユーザーは論文解説でどんな説明順を好む?
こういう質問は、単純なベクトル検索だけだと、似た話題が大量に出てきます。
HiGMemのようにEventを作っておくと、
どの話題の、どの発言か
を探しやすくなります。
注意点
HiGMemはかなり魅力的な設計ですが、実装するときには注意点もあります。
1. 中間LLM呼び出しは増える
HiGMemは、回答LLMに渡すTurnを減らせます。
しかし、その代わりに、メモリ構築や検索時にLLMを多く使います。
Turn metadata生成
Event affiliation
Event update
Event内Turn選択
Final evidence filtering
このあたりでLLMを使うため、A-Memより処理時間は増えます。
つまり、HiGMemは「常に軽い」仕組みではありません。
最終回答の入力:
軽くなる
中間処理:
重くなる
というトレードオフです。
2. Temporal質問には別ルートが必要そう
HiGMemは、TemporalカテゴリではA-Memより低いF1でした。
これは、Event summaryで意味をまとめると、細かい時系列情報が弱くなる可能性があるからです。
たとえば、
最初に話したのはいつ?
前回の修正後に何が起きた?
最後に決めた方針は?
のような質問では、Event summaryだけに頼らない方がよさそうです。
実装では、Temporal質問を検出したときに、timestamp重視の検索ルートを追加するとよいと思います。
通常検索:
Event summary + Turn search
Temporal検索:
timestamp filter
timeline sort
Event history
3. Eventの粒度が重要
Eventが細かすぎると、Turnとほとんど変わりません。
悪い例:
1発言ごとにEventができる
逆に、Eventが大きすぎると、その中からTurnを探す意味が薄くなります。
悪い例:
Androidアプリ開発という巨大Eventに全部入る
ちょうどよい粒度は、話題や作業単位です。
よい例:
Androidアプリの通知改善
Androidアプリの月跨ぎバグ
Androidアプリの履歴画面
AndroidアプリのDataStore設計
Eventは、ただの要約ではありません。
検索の足場です。
だから、Eventの粒度が悪いと、HiGMemの良さも出にくくなります。
4. LLMが作るmetadataは事実ではなく解釈
Turn metadataやEvent summaryは便利です。
ただし、それらはLLMが作った解釈です。
ユーザーが実際に言ったことと、LLMが解釈したことは分けた方が安全です。
raw memory:
実際の発言
derived memory:
keywords
tags
context
summary
fact sheet
この区別をしないと、LLMの誤解が記憶として固定される可能性があります。
まとめ
HiGMemは、長期会話エージェントの記憶検索を「たくさん思い出す」方向から、「読むべき証拠だけを選ぶ」方向へ進める論文です。
従来のメモリ検索では、質問に似ている記憶を多めに取ることで、必要な情報を取り逃がさないようにします。
しかし、その方法では、不要な記憶も増えます。
回答LLMに渡すコンテキストが膨らみ、コストが増え、ノイズも増えます。
HiGMemは、会話記憶をTurn nodeとEvent nodeに分けます。
Turn node:
実際の細かい発言
Event node:
複数のTurnをまとめた出来事
質問時には、Turnを直接検索するだけでなく、Event summaryも検索します。
そして、Eventに紐づくTurnの中から、LLMが読むべきTurnを選びます。
つまり、HiGMemはこういう仕組みです。
関連しそうなTurnを大量に渡す
ではなく、
関連しそうなEventを見つける
↓
その中から読むべきTurnを選ぶ
↓
少数のEvidenceだけ回答LLMへ渡す
A-Memが、記憶を「保存された過去ログ」から「育っていく記憶ノート網」へ変える設計だとすれば、HiGMemは、その育った記憶から「何を読むべきか」を扱う設計です。
LLMチャットアプリやエージェントを作るなら、次の組み合わせはかなり実用的だと思います。
A-Mem的に:
記憶をノート化し、リンクし、進化させる
HiGMem的に:
記憶をEvent-Turn階層に整理し、質問時に読むべきTurnだけを選ぶ
長期記憶で重要なのは、ただ覚えることではありません。
必要なときに、必要な記憶だけを、ちょうどよく思い出せることです。
HiGMemは、その方向にかなり分かりやすく進んだ論文だと思いました。