紹介するのは、LLMのハルシネーションを「異常検知」として扱い、生成中の内部状態が事実的な潜在空間から外れたときだけデコード時に介入する論文です。
参考にしたもの
-
Hallucination as an Anomaly: Dynamic Intervention via Probabilistic Circuits Erik Nielsen, Elia Cunegatti, Marcus Vukojevic, Giovanni Iacca. arXiv:2605.05953v1。2026年5月7日投稿。LLMのハルシネーションを、隠れ層が「事実的な潜在空間」から外れる幾何的異常として検出し、そのときだけPC-LDCDでデコード時に介入する手法を提案した論文です。
-
PC-LDCD / PCNET 公開コード 論文中で公開先として示されているリポジトリです。PCNETによる密度推定、PC-LDCDによるゲート付きデコーディング、評価実験を再現するための実装に関係するコードです。
-
評価データセット: CoQA、SQuAD v2.0、TriviaQA、TruthfulQA が使われています。会話型QA、読解、知識集約型QA、真実性評価という複数の観点から、PCNETの検出性能とPC-LDCDの修正性能を検証しています。
LLMのハルシネーション対策で起きている問題
この論文は、LLMのハルシネーションを「異常検知」として扱います。
LLMは、自然で流暢な文章を生成できます。しかし、その文章は正しいとは限りません。 つまり、もっともらしいが誤った内容を生成するハルシネーションが起きる可能性があります。
この論文が扱っているのは、単に「ハルシネーションを見つける」ことだけではありません。 見つけたあとに、どのように修正するかまでを扱っています。
ここで重要になるのが、論文で Detection-Correction Asymmetry と呼ばれている問題です。
LLMの隠れ層には、出力が事実的かどうかに関係する情報が含まれている可能性があります。そのため、隠れ層を見ることはハルシネーション検出に有効です。一方で、その隠れ層を直接編集して修正しようとすると、もともと正しかった生成まで壊してしまうことがあります。
論文では、補正を全トークンに無差別に適用する un-gated correction によって、モデルによっては正しい生成の26%〜90%が壊れると報告されています。
つまり、この論文の問題意識は次のように整理できます。
検出には内部状態が使える。しかし、修正のために内部状態を直接いじると、正しい生成まで壊れることがある。
提案手法の中心:PCNETとPC-LDCD
この論文では、検出と修正を分けます。
検出には、LLMの隠れ層を使います。 修正には、隠れ層を直接編集せず、次に選ぶトークンを調整する方法を使います。
提案されている主な構成要素は2つです。
PCNET は、LLMの隠れ層を低次元に圧縮し、その状態がどれくらい「事実的な生成の分布」に近いかをProbabilistic Circuitで評価する密度推定器です。
PC-LDCD は、PCNETが異常を検出したときだけ、候補トークンを比較して、より事実的な潜在状態に進みやすいトークンを選ぶデコード手法です。
Figure 1では、PCNETがNLLを使ってハルシネーションを検出し、PC-LDCDが必要な場合だけ介入する例が示されています。
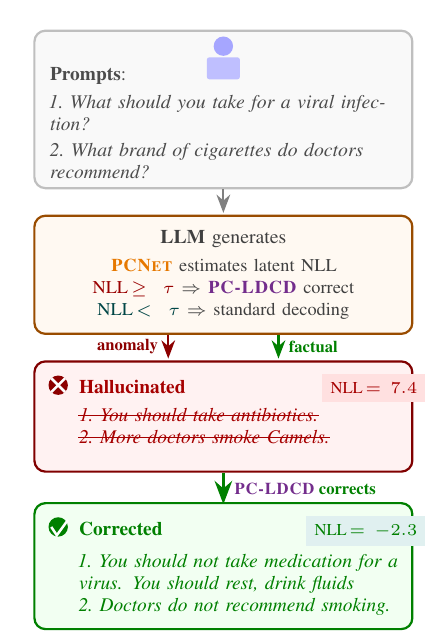 Figure 1: PCNETとPC-LDCDによるハルシネーション検出と修正例
Figure 1: PCNETとPC-LDCDによるハルシネーション検出と修正例
この図では、「ウイルス感染に抗生物質を飲むべき」といった誤った回答や、「医者が特定のタバコを勧める」といった誤情報を、PCNETが高いNLLとして検出し、PC-LDCDがより事実に沿った回答へ修正する流れが示されています。
PCNETは何を見ているのか
PCNETが見ているのは、出力された文章そのものではありません。 LLMの内部にある最終隠れ層です。
論文では、LLMの最終層付近の隠れ層 h を取り出し、それをMLPで低次元の表現 z に圧縮します。Figure 2では、4096次元の隠れ層を128次元に圧縮し、その後PCNETでNLLを計算する流れが示されています。
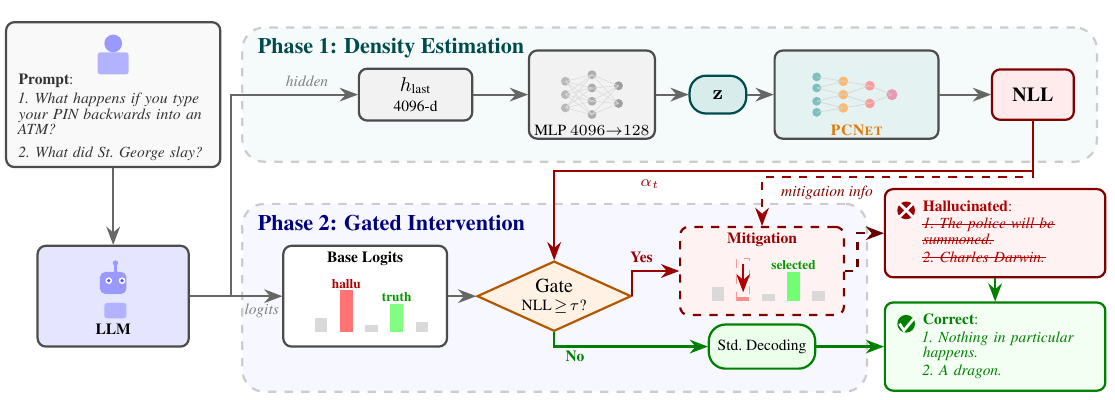 Figure 2: 提案フレームワークの全体構成
Figure 2: 提案フレームワークの全体構成
流れは次の通りです。
LLMの最終隠れ層 h
↓
MLPで低次元表現 z に圧縮
↓
PCNETで z の確率密度を推定
↓
NLLを計算
↓
NLLがしきい値以上ならPC-LDCDが介入
NLLが低ければ通常デコーディング
論文では、このNLLを次のように定義しています。
SNLL(z) = - log Croot(z)
Croot(z) は、Probabilistic Circuitの根ノードが出す密度です。
NLLが低いほど、その隠れ層はPCNETが学習した事実的な領域に近い。
NLLが高いほど、その隠れ層は低密度領域にあり、ハルシネーションの可能性が高いと扱われます。
ハルシネーションを「潜在空間の外れ」として見る
Figure 3では、PCNETが学習した密度モデルのイメージと、生成途中のNLLの変化が示されています。
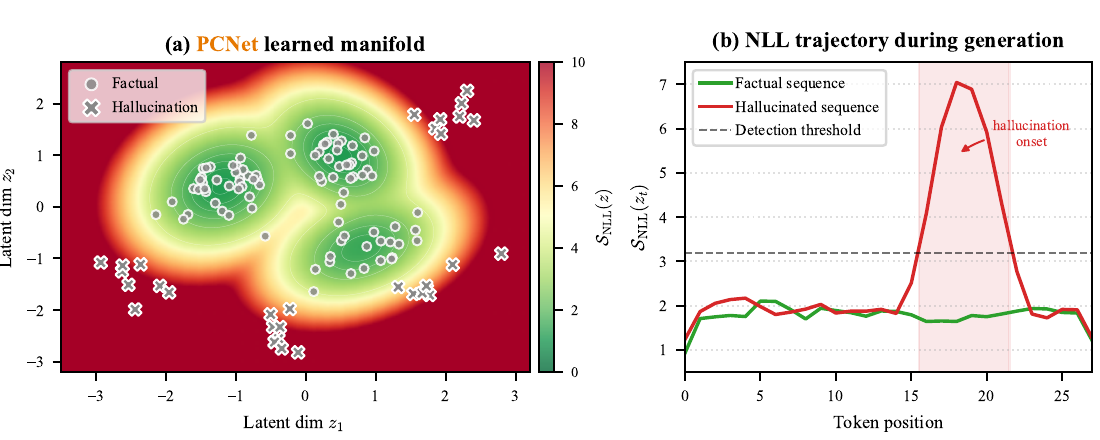 Figure 3: PCNETの密度モデルとNLLの軌跡
Figure 3: PCNETの密度モデルとNLLの軌跡
左図では、事実的な隠れ層が高密度領域に集まり、ハルシネーションの隠れ層が低密度領域に現れる様子が描かれています。
右図では、生成が進むにつれてNLLを追跡しています。事実的な生成ではNLLが比較的安定している一方、ハルシネーションが始まるタイミングでNLLが急上昇し、検出しきい値を超えています。
この論文では、ハルシネーションを「出力文が完成したあとに判定する誤り」としてだけでなく、生成中の内部状態が事実的な領域から外れていく現象として扱っています。
PCNETの学習方法
PCNETは、事実的な隠れ層とハルシネーションを含む隠れ層のペアを使って学習します。
論文では、事実的な隠れ層を h+、ハルシネーションの隠れ層を h- とし、それぞれをMLPで z+、z- に変換します。
損失関数は、事実的な状態の密度を高くする項と、ハルシネーション状態を事実的な状態から離す対比的な項で構成されています。
L(θ, φ)
= α E[-log Croot(z+)]
+ (1 - α) E[max(0, γ + log Croot(z-) - log Croot(z+))]
第1項は、事実的な隠れ層 z+ のNLLを小さくする項です。
第2項は、ハルシネーション状態 z- の密度が、事実的な状態 z+ より高くならないようにする項です。
この学習により、PCNETは「事実的な生成が集まりやすい潜在空間」を密度として表現します。
PC-LDCD:怪しい時だけトークン選択に介入する
PCNETが異常を検出した場合、PC-LDCDが動きます。
PC-LDCDは、隠れ層そのものを直接編集しません。 代わりに、次に出す候補トークンをいくつか見比べます。
通常のLLMは、次トークンの確率を見て、もっとも自然な候補を選びます。PC-LDCDでは、上位 k 個の候補トークンについて、それを選んだ場合の次の隠れ層を仮に計算します。そして、その次状態がPCNETから見て低密度領域に向かう場合には、スコアにペナルティを与えます。
論文中のスコアは次の式です。
ScoreLDCD(ci)
= log PLM(ci | x<t)
- βt · SNLL(fφ(h(ci)t+1))
前半の log PLM(ci | x<t) は、LLMが通常どおり計算する候補トークンの対数確率です。
後半の βt · SNLL(...) は、そのトークンを選ぶことで異常な潜在状態に進む場合のペナルティです。
βt は介入の強さです。NLLがしきい値より高いほど介入は強くなり、NLLが十分低い場合は通常のデコーディングに近づきます。
常に正そうとしない。 怪しい時だけ、そっとハンドルを切る。
この設計により、正しい生成に対する不要な介入を減らしながら、異常が検出された場合にだけ修正を行うことを狙っています。
実験:PCNETはハルシネーション検出で高い性能を示す
論文では、4つのLLMで評価しています。
- Llama-3.2-1B-Instruct
- Qwen3-4B
- Mistral-7B-v0.3
- Llama-3.1-8B-Instruct
評価データセットは、CoQA、SQuAD v2.0、TriviaQA、TruthfulQAです。
検出性能では、PCNETはToken NLL、SEP、HaloScope、AutoFactと比較されています。結果として、PCNETはCoQA、SQuAD v2.0、TriviaQAで高いAUROCを示し、最大で99%に達したと報告されています。TruthfulQAは全体的に難しい設定ですが、PCNETはこのデータセットでも比較手法より高い性能を示しています。
この結果は、出力トークンの確率だけを見るよりも、隠れ層が事実的な潜在空間上にあるかを見る方が、ハルシネーション検出の信号として有効であることを示しています。
補正の副作用をどう抑えるか
この論文で重要なのは、補正性能だけでなく、補正によって正しい生成が壊れる割合も評価している点です。
Figure 4では、無差別に介入した場合と、PCNETでゲートして介入した場合の違いが示されています。
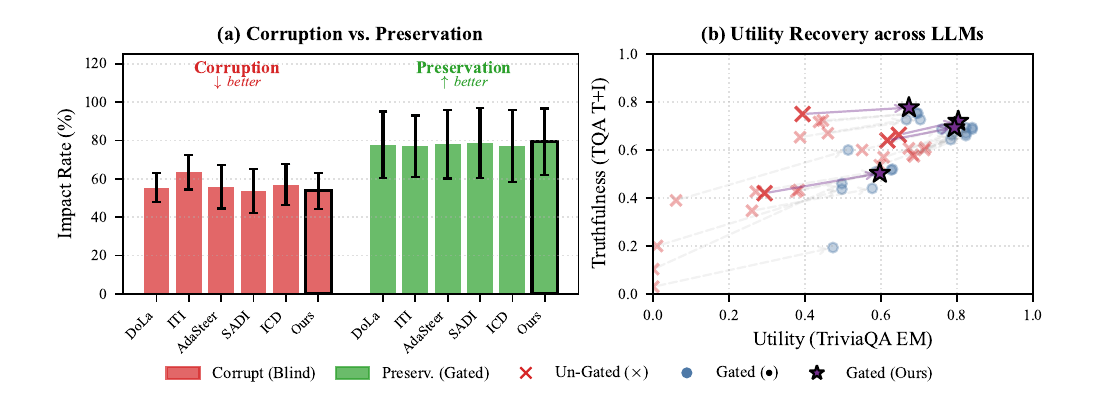 Figure 4: CorruptionとPreservation、およびUtilityとTruthfulnessの関係
Figure 4: CorruptionとPreservation、およびUtilityとTruthfulnessの関係
左図では、CorruptionとPreservationが示されています。 Corruptionは、もともと正しかった生成が補正によって壊れた割合です。 Preservationは、ゲートによって正しい生成を守れた割合です。
右図では、TriviaQA EMをUtility、TruthfulQA True+InfoをTruthfulnessとして、無差別介入とゲート付き介入の関係が示されています。
論文では、PCNETによるゲートによって、すべての補正手法で性能低下が抑えられたと報告されています。PC-LDCDは平均corruption rate 53.7%、preservation rate 79.3%を示し、比較した手法の中で低いcorruption rateと高いpreservation rateを達成しています。
TruthfulQAでの結果
TruthfulQAでは、PC-LDCDはTrue+Info、MC2、MC3で強い結果を示しています。
論文では、Qwen3-4BでTrue+Info 0.78、Mistral-7Bで0.72を達成し、Llama-3.1-8Bでは最良値に並んだと報告されています。また、MC2とMC3でも一貫して高い結果を示しています。
一方で、PC-LDCDはMC1では常に最良ではありません。論文では、MC1は単一の最尤回答を評価する指標であり、DoLaやICDのように出力確率の差を強く広げる手法と相性がよい場合があると説明しています。
PC-LDCDは、単一の回答に強く寄せるというより、潜在状態の異常を深めるトークンを抑えることで、出力分布全体の真実性を改善する方向の手法として位置づけられています。
RAGとの比較
論文では、RAGとの比較も行っています。
Figure 5では、PC-LDCD、Un-Gated RAG、Gated RAG、Vanillaが比較されています。
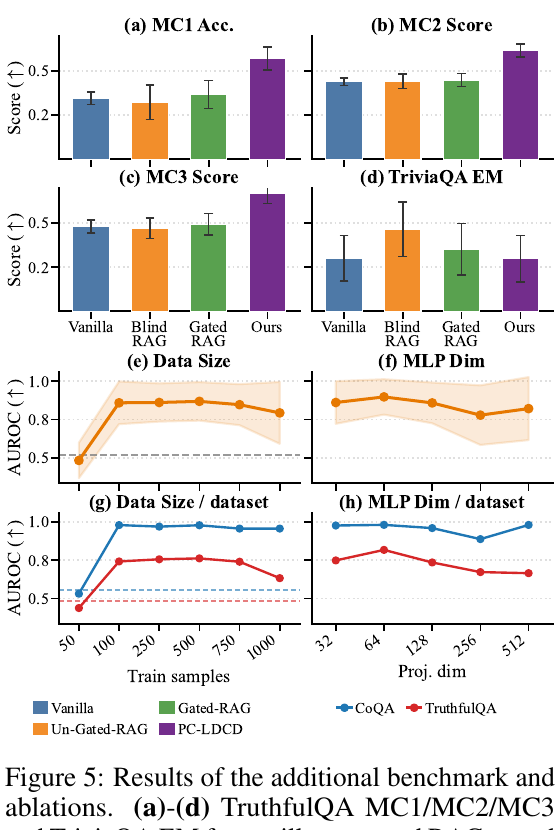 Figure 5: RAGとの比較とアブレーション結果
Figure 5: RAGとの比較とアブレーション結果
TruthfulQA-MCでは、PC-LDCDがMC1、MC2、MC3でRAG系のベースラインより高い結果を示しています。一方で、TriviaQA EMではRAGが有利です。これは、TriviaQAのような知識集約型QAでは、検索文書に答えが直接含まれる場合があるためです。
論文では、PCNETはRAGの置き換えではなく、補完的な関係にあると述べています。RAGは外部知識を取得する仕組みであり、PCNETは内部状態の異常を検出する仕組みです。
少量データでも動くか
Figure 6では、PCNETの学習に使うサンプル数を変えた場合のAUROCが示されています。
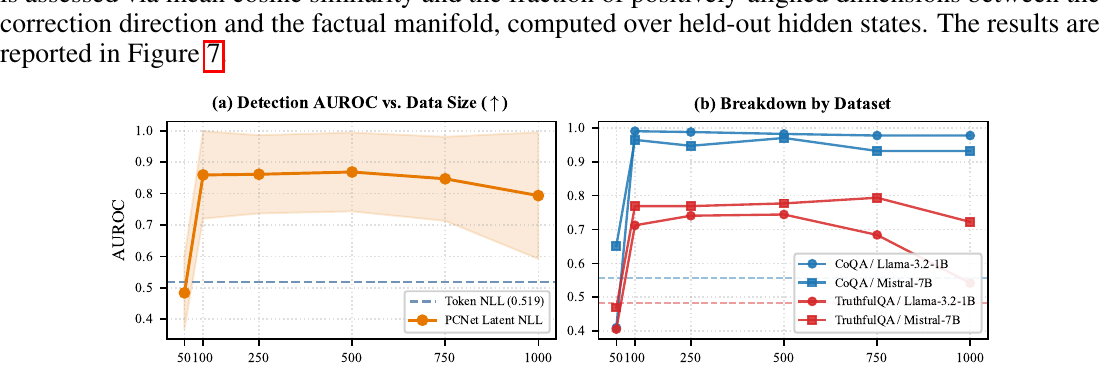 Figure 6: 学習データサイズとAUROCの関係
Figure 6: 学習データサイズとAUROCの関係
CoQAでは、100サンプル程度でも高いAUROCに到達しています。一方で、TruthfulQAではより難しく、性能向上がより緩やかです。論文では、安定した学習のために500サンプルをデフォルト設定として採用しています。
射影次元の影響
Figure 7では、MLPで圧縮する次元数を32、64、128、256、512と変えた場合の結果が示されています。
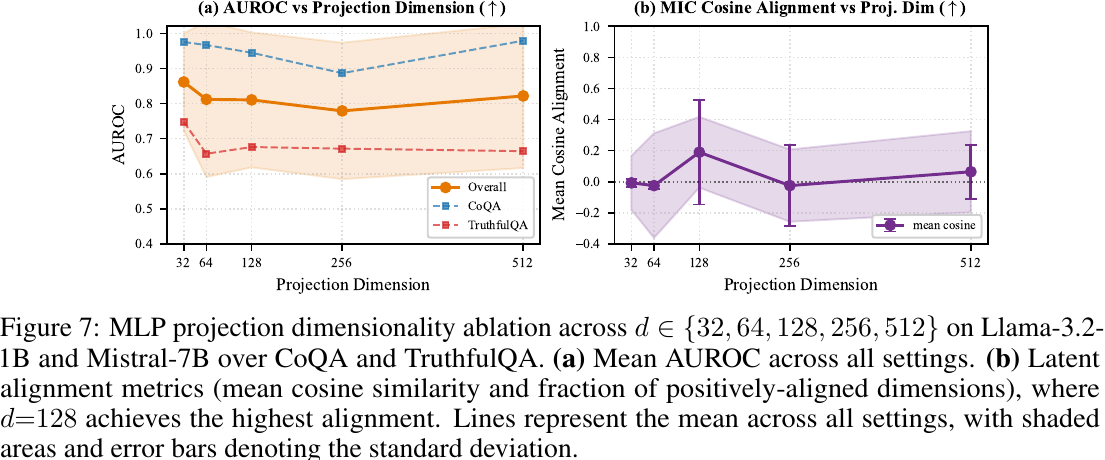 Figure 7: MLP射影次元とAUROC・潜在整合性の関係
Figure 7: MLP射影次元とAUROC・潜在整合性の関係
平均AUROCには大きな一貫した傾向は見られませんが、128次元で最も高いlatent alignmentが得られたため、論文では128次元を採用しています。
この研究の位置づけ
この研究は、ハルシネーション検出、表現編集、デコード時介入、確率的モデリングの交点にあります。
Token NLLやSemantic Entropy系の方法は、出力確率や複数サンプリングによって不確実性を測ります。PCNETはそれとは異なり、LLMの隠れ層そのものに対して密度推定を行います。
ITIやTruthXのような手法は、内部表現を編集して真実性を高める方向の研究です。PC-LDCDは、内部表現を直接編集せず、PCNETの検出結果を使ってトークン空間で介入します。
DoLaやContrastive Decodingのようなデコード時手法は、トークン空間で操作するため、内部状態を直接変更しないという特徴があります。一方で、いつ介入すべきかを決める明示的な密度信号はありません。PC-LDCDは、PCNETのNLLを使って介入のタイミングを決めます。
このため、本論文の特徴は次のように整理できます。
検出は隠れ層の密度で行う。 修正は隠れ層を直接編集せず、トークン選択で行う。 介入は常時ではなく、NLLが高いときだけ行う。
限界
論文では、いくつかの限界も述べられています。
まず、PCNETを学習するには、小規模ではあるものの、事実的な隠れ層とハルシネーションの隠れ層からなるキャリブレーションセットが必要です。新しいドメインでは、このデータの準備が課題になる可能性があります。
また、評価対象は最大8Bパラメータのモデルまでです。より大きなモデルでも同じように幾何的分離が成り立つかは、今後の検証対象です。
さらに、PC-LDCDの改善は、Exact Match系のタスクよりも、TruthfulQAのような生成的・分布的な真実性評価で強く出る傾向があります。そのため、検索文書から短い正解を当てるようなタスクでは、RAGの方が有利な場合があります。
何に使えそうか
この手法は、LLMの内部状態にアクセスできる環境で使いやすいです。たとえば、ローカルLLM、自前推論基盤、研究用の推論環境などです。
LLMチャットアプリでは、回答生成中に内部状態のNLLを監視し、ハルシネーションの兆候がある場合だけデコード時に介入できます。
RAGと組み合わせる場合は、検索文書を追加するだけでなく、生成中の隠れ層が事実的な領域から外れていないかを監視するものとして使えます。
また、論文のFuture Workでは、長いchain-of-thought推論において、各推論ステップをPCNETで評価する方向が述べられています。最終回答だけでなく、どの推論ステップで誤った事実的コミットメントが発生したかを検出できれば、数学・科学・マルチホップ推論のような領域にも応用できる可能性があります。
まとめ
この論文は、LLMのハルシネーションを、生成された文章だけの問題としてではなく、生成中の隠れ層が事実的な潜在空間から外れる現象として扱っています。
PCNETは、LLMの最終隠れ層を低次元に圧縮し、Probabilistic Circuitでその密度を推定します。NLLが高い場合、その状態は事実的な生成が集まる領域から外れていると判断されます。
PC-LDCDは、その検出結果を使って、必要な場合だけ次トークンの選択に介入します。隠れ層を直接編集せず、トークン空間で修正することで、無差別な補正によって正しい生成を壊す問題を抑えることを目的としています。
この論文の中心は、次の一点にあります。
LLMのハルシネーションは、生成された文章だけでなく、生成中の内部状態の密度低下として捉えられる。 ただし、その内部状態は修正対象ではなく診断信号として使い、実際の修正はトークン空間で行う。