参考にしたもの
- Hidden Technical Debt in Machine Learning Systems D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-François Crespo, Dan Dennison. NIPS 2015。機械学習システムでは、モデルコードそのものよりも、データ依存関係、特徴量、設定、パイプライン、監視、フィードバックループ、組織文化の中に技術的負債が蓄積することを整理した論文です。
概要
Hidden Technical Debt in Machine Learning Systemsは、機械学習システムは素早く作れても長期運用で保守コストが増える問題を「技術的負債」という枠組みで説明しています。MLコード以上に周辺のデータ依存、特徴量、設定、監視、組織文化が影響を受け複雑化してしまうことを伝えています。少しの精度改善や便利な依存追加のために、将来の変更や削除を難しくしてしまう可能性を伝えています。
機械学習は「動くもの」をすぐに作れるが、「結果を保ち続ける」のが難しい
機械学習は、複雑な予測システムを素早く作るための強力な道具です。 データを用意し、特徴量を作り、モデルを学習させると、短い時間で「それなりに動くもの」ができます。
しかし、この「すぐ動く」は一定の結果を保証するものではありません。 論文では、機械学習システムは開発とデプロイは比較的速くできる一方で、長期的に保守するのが難しく維持するのが大変になりやすい、と述べています。 これを説明するために使われているのが technical debt、技術的負債 です。 技術的負債という言葉は、急いで開発するために将来の保守コストを背負う、という考え方です。 もちろん、すべての負債が悪いわけではありません。短期的に前に進むために、意図的に負債を取ることもあります。 ただ、負債には利息があります。 コードのリファクタリング、テストの改善、不要コードの削除、依存関係の整理、APIの明確化、ドキュメント整備を後回しにすると、あとから変更するコストが膨らんでいきます。 論文では、特に Hidden debt is dangerous because it compounds silently、つまり隠れた負債は静かに複利で増えるため危険だ、という趣旨の説明がされています。
MLシステムの怖さは、負債がコードの外にたまること
普通のソフトウェアでも技術的負債はあります。 しかし、この論文が強調しているのは、MLシステムではそれに加えて ML固有の負債 が加わるということです。 コードが複雑になるだけではありません。
データが変わる。 特徴量が増える。 別のモデルの出力を使う。 パイプラインが伸びる。 設定ファイルが増える。 本番のユーザー行動が変わる。 モデルの出力を別システムが勝手に使い始める。 監視すべきものが見えなくなる。
このように、MLシステムでは、負債がコードの中だけでなく、データ、特徴量、設定、システム間の関係、外部世界との相互作用にたまります。 ここがこの論文の重要なところです。
MLシステムの実運用では、モデルがどのデータから学習され、どの特徴量に依存し、誰に使われ、どの設定で動き、外部世界からどう影響を受けるかまで含めて、ひとつのシステムになります。
MLコードは、全体のほんの一部でしかない
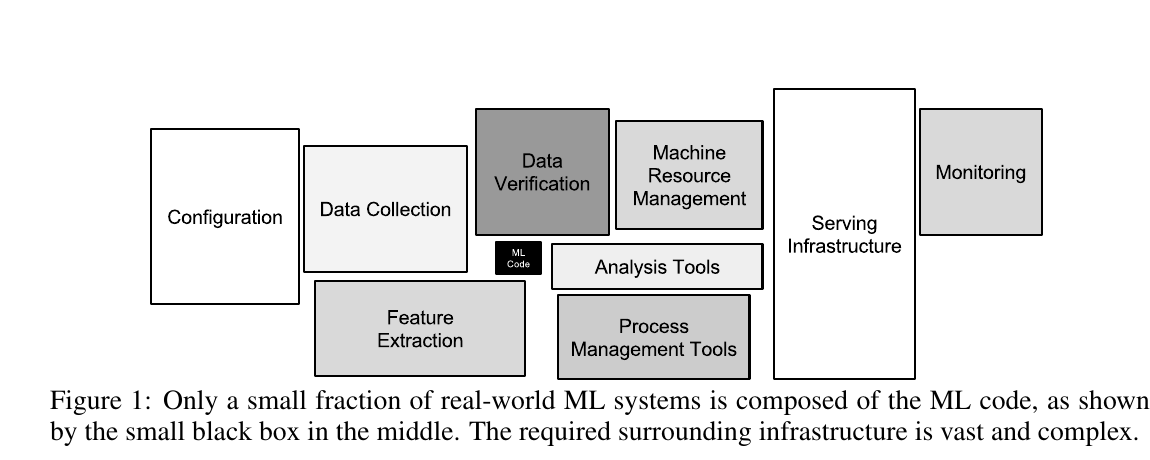 Figure 1: 実世界のMLシステムにおけるMLコードと周辺インフラ
Figure 1: 実世界のMLシステムにおけるMLコードと周辺インフラ
この図では、中央に小さな黒い箱として ML Code が描かれています。
一方で、その周りには、Data Collection、Data Verification、Feature Extraction、Configuration、Machine Resource Management、Analysis Tools、Process Management Tools、Serving Infrastructure、Monitoring などが大きく配置されています。
論文の説明では、実世界のMLシステムにおいて、MLコードは全体のごく一部であり、必要な周辺インフラが多くの割合を占めています。 本番環境で動かそうとすると、急にMLシステム以外の要素の割合が大きくなります。
データは毎日正しく届いているのか。 特徴量の定義は変わっていないか。 学習時と推論時で同じ前処理になっているか。 設定ファイルの差分は追えるか。 モデルの出力を誰が使っているか。 本番で異常が起きたときに検知できるか。 精度が下がったとき、それはモデルの問題なのか、データの問題なのか、外部世界の変化なのか。
複雑なモデルは境界を侵食する
通常のソフトウェア設計では、モジュールの境界が重要です。
ある部品はこの入力を受け取り、この出力を返す。 内部の実装は外から見えない。 変更しても影響範囲が閉じている。
こうした抽象化境界があるから、ソフトウェアは保守できます。
しかしMLではこの境界が崩れやすい、と論文では説明されています。 理由は、MLシステムの振る舞いがコードだけでなく、データに強く依存するからです。 そもそもMLは、望ましい振る舞いをソフトウェアのロジックとして直接書けない場合に使われます。 そのため、現実世界のデータがシステムの振る舞いを決めます。
ここで出てくる重要な概念が Entanglement です。
あるモデルが x1, x2, ..., xn という特徴量を使っているとします。
このとき、x1 の分布が変わると、残りの特徴量の重要度や重みの使われ方も変わる可能性があります。
新しい特徴量を1つ足しても変わる。 古い特徴量を1つ消しても変わる。 サンプリング方法を変えても変わる。 ハイパーパラメータを変えても変わる。 学習データの選び方を変えても変わる。
論文ではこれを CACE principle と呼びます。
Changing Anything Changes Everything
何かを変えると、すべてが変わる。
通常のソフトウェアなら「この関数だけ直せばよい」と言える場合があります。 しかしMLでは、特徴量やデータの変更がモデル全体の振る舞いに広がることがあります。
少し直すための補正モデルが、将来の改善を止める
論文では Correction Cascades という問題も説明されています。
たとえば、ある問題Aを解くモデル ma がすでにあるとします。
そこから少し違う問題A'を解きたい。
このとき、ma の出力を入力にして、少しだけ補正するモデル m'a を作るのは、短期的には便利です。
すでにあるモデルを使える。 新しいモデルを一から作らなくてよい。 少しの差分だけ学習すればよい。
しかし、ここで新しい依存関係ができます。
A'のモデルは、元の ma に依存します。
さらにその上に、A''用の補正モデルを重ねると、補正の連鎖ができます。
すると将来、元の ma を改善したときに、その改善が下流の補正モデルを壊す可能性があります。
個別には改善なのに、システム全体では悪化する。
この状態を論文では improvement deadlock として説明しています。
誰がモデル出力を使っているのか分からない
次に出てくるのが Undeclared Consumers です。 これは、モデルの出力を、宣言されていない利用者が使っている状態です。
たとえば、あるモデルの予測結果がログやテーブルに保存されているとします。 別チームや別システムが、その値を便利だから使い始める。
この状態で元モデルを改善すると、別システムが壊れることがあります。 元モデルのチームから見ると、「精度を上げただけ」です。 しかし別チームの誰かは、その古い出力分布を前提に別のロジックを組んでいるかもしれません。
論文では、Undeclared Consumersは高コストであり、場合によっては危険だと述べています。 モデルの変更が、意図せずスタックの別部分に影響するからです。 対策として、アクセス制御やSLAなど、誰が何を使っているかを明確にする仕組みが必要になります。
データ依存はコード依存より見えにくい
この論文で非常に重要なのが、Data Dependencies Cost More than Code Dependencies という節です。
コードの依存関係は、ある程度見ることができます。 コンパイラ、リンカ、ビルドシステム、静的解析ツールで追跡できます。
しかし、MLシステムのデータ依存は見えにくいです。
その特徴量はどこから来たのか。 誰が作っているのか。 定義はいつ変わったのか。 別のMLモデルの出力ではないのか。 本番と学習で同じ意味なのか。 もう使っていないのに残っていないか。
こうした依存関係は、コード上のimportのようには見えません。 そのため、大きな依存関係の鎖が静かに作られ、あとからほどけなくなります。
論文では、特に Unstable Data Dependencies と Underutilized Data Dependencies が説明されています。
Unstable Data Dependenciesは、時間とともに意味や分布が変わる特徴量です。 たとえば、別のMLモデルの出力、更新されるテーブルデータ、TF-IDFスコア、意味クラスタなどです。 上流側では改善のつもりで変更しても、下流モデルは古い歪みに適応しているため、突然の悪影響が出る可能性があります。
Underutilized Data Dependenciesは、性能にはほとんど寄与していないのに、システムを壊れやすくしている特徴量です。 古い特徴量、まとめて入れた特徴量、ほんの少しだけ精度を上げる特徴量、相関しているだけで因果的ではない特徴量などが該当します。
ここは、機械学習をやっているとかなり耳が痛いところです。
「少し精度が上がるから入れておこう」 「あとで消せばいいから残しておこう」 「古い特徴量も念のため入れておこう」
この「念のため」が、後の保守コストになります。
モデルは世界を変え、世界はモデルを変える
本番環境のMLシステムは、ただ世界を観測しているわけではありません。 世界に影響します。
推薦モデルは、ユーザーが何を見るかを変えます。 広告モデルは、ユーザーが何をクリックするかを変えます。 スパム判定モデルは、送信者の行動を変えます。 検索ランキングは、どのページが読まれるかを変えます。
その結果、将来の学習データも変わります。
論文では、これを Feedback Loops として整理しています。 直接的なフィードバックループでは、モデルが自分の将来の訓練データの選択に影響します。 本来はbanditアルゴリズムのような方法が適切になる場合もありますが、現実の大規模システムでは簡単ではありません。
さらに難しいのが Hidden Feedback Loops です。 これは、2つのシステムが世界を介して間接的に影響し合う場合です。 たとえば、あるシステムが商品を選び、別のシステムがレビューを選ぶとします。 片方を改善すると、ユーザー行動が変わり、もう片方の入力分布も変わる可能性があります。
つまり、コード上では依存していないのに、現実世界を介して依存している。
これは検出が難しいです。 システム図には線がないのに、実際にはつながりがあるからです。
Glue CodeとPipeline Jungle
論文では、MLシステムで起こりやすいアンチパターンも説明されています。
まず Glue Code です。
汎用的なMLパッケージを使うと、その入出力に合わせるための周辺コードが増えます。 データをその形式に合わせる。出力を別形式に変換する。評価に渡す。ログに詰める。 このようなコードが大量に増えると、システムは特定のパッケージの仕様に固定されます。 別の手法を試したくても、周辺コードが固定されてしまい試すことができなくなります。
次が Pipeline Jungles です。
データ準備の処理は、最初は小さく始まります。 しかし、新しいデータソース、新しい特徴量、新しいjoin、新しいサンプリング、新しい中間ファイルが増えていくと、いつの間にか複雑になります。
この状態では、障害の原因を探すのが難しくなります。 テストも、単体テストではなく重いend-to-endテストに頼りがちになります。 そして、さらに新しい改善を入れるコストが上がります。
実験用コードが本番に残る
論文では Dead Experimental Codepaths も取り上げています。
実験のために、本番コード内に条件分岐を追加する。 一度試した手法のフラグを残す。 古い処理を消さずに残す。 特定条件だけ旧処理を通す。
短期的には便利です。周辺インフラを作り直さずに実験できるからです。
しかし、こうした実験分岐が積み重なると、保守が難しくなります。 どの分岐がまだ使われているのか分からない。 組み合わせが増え、テスト実施が難しくなります。
論文では、古い実験コードパスの危険性の例として、Knight Capitalの事例にも触れています。 これは、古い実験的コードパスによる予期しない挙動が大きな損失につながった例として紹介されています。
設定ファイルも技術的負債になる
機械学習システムでは、設定も大きな負債になります。
使う特徴量。 学習データの期間。 サンプリング条件。 学習率。 正則化。 前処理。 後処理。 しきい値。 検証方法。 本番配信時のオプション。
成熟したシステムでは、設定ファイルの行数が通常のコード行数を超えることもある、と論文では述べています。 そして、設定の各行にはミスの可能性があります。
論文では、設定にまつわるミスの例が挙げられています。
ある特徴量は特定期間だけ誤ってログされていた。 別の特徴量はある日付以前には存在しない。 ログ形式の変更により、日付の前後で特徴量計算を変える必要がある。 本番環境では使えない特徴量がある。 ある特徴量を使うと追加メモリが必要になる。 ある特徴量はレイテンシ制約のため別の特徴量と同時に使えない。
こうなると、設定は単なるパラメータではありません。 システムの振る舞いを決める重要なコードに近いものです。
そのため論文では、設定もコードレビューされ、リポジトリに保存され、自動検証されるべきだと述べています。
外部世界は変わる
機械学習システムは、外部世界とつながっています。 そして外部世界は安定していません。
ユーザー行動が変わる。 商品が変わる。 スパムの手口が変わる。 市場が変わる。 入力データの分布が変わる。 上流システムの仕様が変わる。
論文では、固定しきい値の問題が説明されています。 たとえば、メールをスパムと判定するしきい値、広告を表示するしきい値、あるアクションを実行するしきい値などです。 モデルが新しいデータで更新されると、以前手で決めたしきい値が合わなくなることがあります。
そのため、MLシステムではテストだけでなく、本番監視が重要になります。
論文では、監視対象としてPrediction Bias、Action Limits、Up-Stream Producersが挙げられています。
Prediction Biasは、予測ラベルの分布と実際の観測ラベルの分布のずれを見る方法です。 Action Limitsは、システムが現実世界に対して取り得る行動に上限を設ける方法です。 Up-Stream Producersは、学習システムにデータを供給する上流プロセスを監視する考え方です。
この論文が今も重要な理由
この論文は2015年のものですが、今のLLMアプリやRAGシステムにもかなり当てはまります。
たとえば、RAGシステムを作るとします。
PDFを読む。 チャンクに分ける。 embeddingを作る。 ベクトルDBに入れる。 検索する。 再ランキングする。 プロンプトに追加。 LLMで回答する。 回答を評価する。 ログを保存する。 必要なら人間が修正する。
この中で、LLMを呼ぶコードだけを見れば小さいシステムです。 しかし、実際の負債はその周辺にたまります。
チャンク分割の設定を変えたら、過去の評価と比較できるのか。 embeddingモデルを変えたら、古いベクトルはどうするのか。 検索クエリ生成を変えたら、再ランキングとの関係はどうなるのか。 プロンプトを変えたら、失敗例の原因分析はやり直しになるのか。 別の機能が回答ログを使い始めていないか。 評価用LLMを変えたら、スコアの意味は同じなのか。
これはまさに、論文が言う「MLコードの外側にある技術的負債」です。
何に使える考え方か
この論文は、MLOpsやLLMOpsの設計チェックリストとして使えます。
新しい特徴量やデータソースを足すとき、それは本当に必要か。 その依存関係は追跡できるか。 将来削除できるか。 モデル出力を誰が使っているか分かるか。 設定はレビューされているか。 実験コードが本番に残っていないか。 本番で何を監視するか決まっているか。 精度改善のために、どれだけ複雑性を増やしているか。
論文の結論では、わずかな精度改善のために大きなシステム複雑性を背負う研究的解決は、実務上は適切でない場合が多いと述べています。 また、一見無害に見える1つか2つのデータ依存関係の追加でさえ、将来の進行を遅らせる可能性があるとしています。
精度が0.1%上がる。 でもパイプラインが複雑になる。 依存関係が増える。 設定が増える。 監視対象が増える。 再現性が落ちる。 削除できなくなる。
このとき、本当にその0.1%は重要で今後も安定して出すことができるのか。 この問いを持つための論文です。
まとめ
Hidden Technical Debt in Machine Learning Systems は、機械学習システムの難しさを、モデル単体ではなく、長期運用されるシステム全体の保守問題として捉えた論文です。
MLコードは、実世界のMLシステムのごく一部でしかありません。 その周囲には、データ収集、特徴量抽出、検証、設定、監視、配信基盤、分析ツール、プロセス管理があります。
短期的な精度改善、便利な特徴量追加、補正モデル、実験分岐、手作業の設定変更は、後から見ると技術的負債になります。
この論文の中心は、次の一点にあります。
機械学習システムにおける技術的負債は、コードの中だけにあるのではなく、データ、特徴量、設定、モデル出力の利用者、外部世界との相互作用、そしてチーム文化の中に隠れて蓄積します。