参考にしたもの
- Time to REFLECT: Can We Trust LLM Judges for Evidence-based Research Agents? Leyao Wang, Yanan He, Peng Chen, Asaf Yehudai, Yixin Liu, Rex Ying, Michal Shmueli-Scheuer, Arman Cohan. arXiv:2605.19196v1。2026年5月18日投稿。Deep research agentの出力や実行過程を評価する LLM-as-a-Judge そのものが信頼できるのかを検証するため、制御された失敗を入れたメタ評価ベンチマークREFLECTを提案した論文です。
Contents
- LLM-as-a-Judge を評価する
- これまでの LLM-as-a-Judge の問題
- REFLECTとは
- 失敗の種類をどう分けているのか
- ベンチマークの作り方
- 数式で見るREFLECTの評価形式
- ジャッジの評価インターフェース
- 実験設定
- 現在の LLM-as-a-Judge は十分に信頼できるとは言いにくい
- 細かく見る評価は、全体評価より失敗を見つけやすい
- どの失敗を見落としやすいのか
- Best-of-Nではさらに難しくなる
- この論文で示されていること
- 限界
- まとめ
LLM-as-a-Judge を評価する
今日紹介するのは、Deep Research系のエージェントを評価するための論文です。
タイトルは Time to REFLECT : Can We Trust LLM Judges for Evidence-based Research Agents?。
RAG だけでなく、ユーザーのクエリに対して、検索やブラウザ操作、ツール使用、複数ステップの推論を行い、証拠に基づく長文レポートを作成する Deep research agent が使われるようになってきました。 このようなエージェントを評価するのにも LLM-as-a-Judge を使い LLM でこのようなエージェントを評価することが考えられます。 しかし、安易に LLM-as-a-Judge を使ってよいのでしょうか。 この疑問を正面から扱っているのが、この論文です。
これまでの LLM-as-a-Judge の問題
既存の LLM-as-a-Judge では、人間の評価とどれくらい一致するかを見ることが多いです。 しかし、Deep research agent の評価にはこれだけでは足りないとしています。
その理由は3つあります。
1つ目は、ラベルが粗く主観的になることです。 「どちらのレポートがよいか」は分かっても、ジャッジがどの失敗を検出できて、どの失敗を見落としたのかまでは分かりにくいです。
2つ目は、正解がないことです。 数学やコードのように、正解が明確なタスクなら評価できます。しかしDeep research agentは、検索、証拠収集、推論、統合を行なうため、その結果をまとめた唯一正解のレポートがあるとは限りません。
3つ目は、最終出力だけではなく、途中の実行過程も重要なことです。 検索の仕方が悪い、証拠を拾い損ねた、ツールを間違って使った、取得したソースを誤解した、といった失敗は、最終レポートだけを見る評価だけでは見落とされることがあります。
この論文では、こうした問題を避けるために、 LLM-as-a-Judge を「人間の好みとの一致」ではなく、「既知の失敗を検出できるか」という形、 REFLECT で評価することを提案しています。
REFLECTとは
REFLECTは、REliable Fine-grained LLM judge Evaluation via Controlled inTervention の略です。
まず、エージェントの実行ログと最終レポートを用意します。 次に、その中の特定の箇所だけを編集し、意図的に失敗を入れます。 そして、失敗を入れる前の実行と、失敗を入れた実行を LLM-as-a-Judge に評価させます。 LLM-as-a-Judge が信頼できるなら、失敗を入れていない元の実行の方を高く評価するはずです。
これにより、評価ラベルを明確に作ることができます。 つまり、「どちらが人間に好まれるか」という抽象的な指標ではなく、「どちらに失敗が入っているか」という明確な指標を評価ラベルにすることができます。
論文では、REFLECTの利点として、検証可能なground-truth label、現実的な失敗分類、細粒度な診断信号の3つを挙げています。特に、既知の失敗タイプと失敗位置を持つため、 LLM-as-a-Judge がどの種類の失敗を見落とすかを調べられます。
失敗の種類をどう分けているのか
こちらでは、REFLECTの失敗分類とデータ分布が示されています。
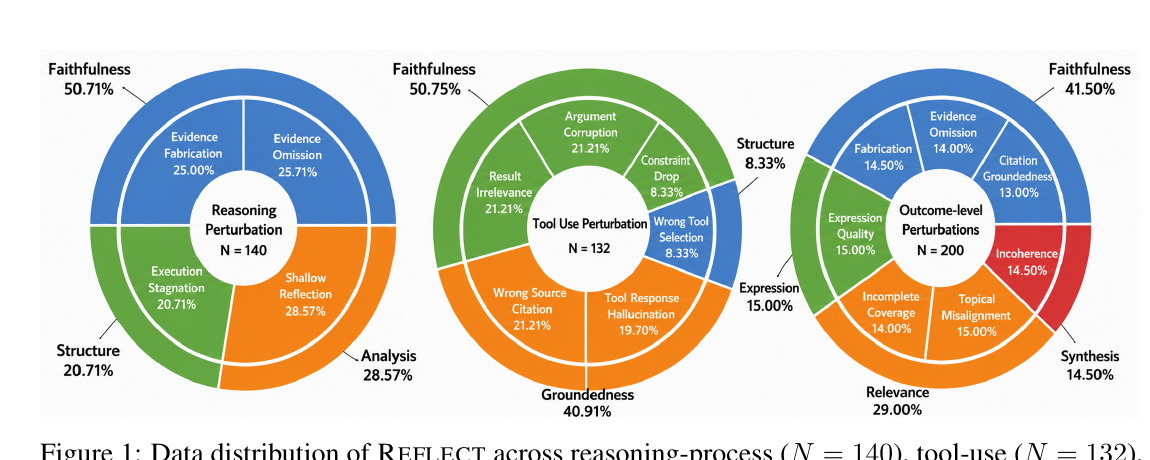
この図では、失敗を大きく3つに分けています。
Reasoning process は、エージェントの推論過程での失敗です。 Tool use は、検索やツール呼び出しの失敗です。 Outcome-level は、最終レポートの品質に関する失敗です。
Reasoning processには、捏造、省略、考察不足などが含まれます。Tool useには、誤ったツール選択、制約の脱落、ツール引数の誤り、無関係な検索結果、誤ったソース引用、ツール応答に基づくハルシネーションなどが含まれます。 Outcome-levelには、根拠の裏付け不足、省略、捏造、表現の質、網羅性の欠如、主題と関係ない内容、一貫性の欠如などが含まれます。
この分類があることで、単に「このジャッジは正答率が高いか」ではなく、 「引用の裏づけが弱い」、「ツール選択に誤りがある」 「最終レポートは読みやすいが、証拠の捏造を見落とす」というように、失敗をタイプごとに評価できます。
ベンチマークの作り方
Figure 2では、REFLECTのベンチマーク構築パイプラインが示されています。
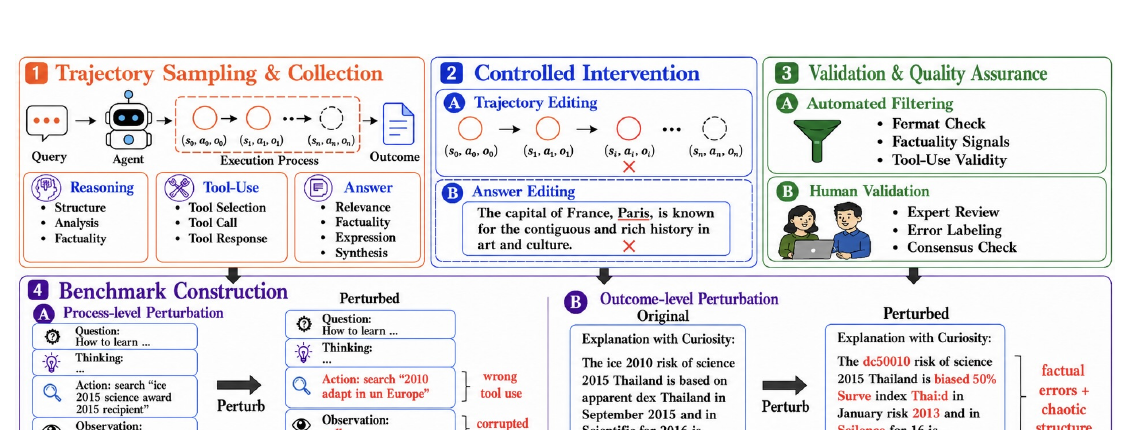
流れは4段階です。
最初に、エージェントの実行ログを集めます。 次に、推論、ツール使用、最終回答に対して、制御された局所的な編集を行います。 その後、自動フィルタと人間のレビューで品質を確認をします。 最後に、元の実行と失敗入りの実行をペアにすることで、ベンチマークを作ります。
ポイントは、失敗を入れるときに、全体を大きく書き換えないことです。
論文では、失敗を入れる箇所は局所的で、もっともらしく、最小限にすべきとしています。 大きく変更すると、ジャッジが本当の失敗ではなく、表現の違いを拾う可能性があります。
そのため、REFLECTでは、周囲の文脈を保ちつつ、特定の失敗だけを入れるようにしています。 人間の検証では、2人のNLP専門知識を持つ注釈者が、失敗が正しく入っているか、元の実行にその失敗がないか、余計な失敗が入っていないかを確認します。 注釈者間一致はκ = 0.86と報告されています。
数式で見るREFLECTの評価形式
論文では、エージェントの実行を次のように表します。
ξ = (q, τ, y)
q はユーザーの質問、τ はエージェントの実行ログ、y は最終回答です。
実行ログ τ は、ReAct型の考え方に沿って、推論、ツール呼び出し、ツール応答の列として表されます。
τ = ((rt, ct, st))^T_{t=1}
rt はその時点の推論、ct はツール呼び出し、st はツールから返ってくる応答です。
REFLECTでは、元の結果を確認した実行を ξ* とし、そこに特定の失敗 f を入れたものを ξ~ とします。
ξ~ = Πf(ξ*)
Πf は、失敗タイプ f に対応する失敗を入れた操作です。
ベンチマークの1インスタンスは、次のような形になります。
bi = (ξ*i, ξ~i, fi, ℓi)
ここで fi は失敗タイプ、ℓi は編集された場所です。プロセスレベルの失敗ならログの中のステップ、アウトカムレベルの失敗なら最終回答中のチャンクになります。
つまり、REFLECTは「このレポートは何点か」を見るだけでなく、「この場所にこの種類の失敗を入れたとき、ジャッジはそれを見抜けるか」を見ることができます。
ジャッジの評価インターフェース
論文では、 LLM-as-a-Judge の使われ方として、3つの形式を扱っています。
1つ目は Scalar judging です。
これは、各実行にスコアを付ける方法です。元の実行 ξ* のスコアが、失敗入りの実行 ξ~ より高ければ成功です。
ΔJ(ξ*, ξ~) = SJ(ξ*) - SJ(ξ~)
2つ目は Pairwise judging です。 元の実行と失敗入りの実行を直接比較し、どちらがよいかを選ばせます。
3つ目は Ranking judging です。 複数の候補の中から最もよいものを選ばせます。これはBest-of-Nやrerankingに近い設定です。
この3つを分けているのは、 LLM-as-a-Judge が実際にはいろいろな使われ方をするからです。評価用スコアとして使う場合もあれば、複数候補から一番よい回答を選ぶ場合もあります。
実験設定
論文では、open-weightモデルとproprietaryモデルの両方を LLM-as-a-Judge として評価しています。
open-weight側には、Qwen3-8B、Qwen3-32B、Qwen3-235B-A22B、Llama-3.1-70B、Gemma3-27B、GPT-OSS-120Bなどが含まれます。proprietary側には、Gemini系、GPT系、Claude系のモデルが含まれます。
評価対象は2つあります。
1つは、エージェントの実行過程です。 これは、推論の流れ、検索、ツール選択、ツール応答の解釈などを見ます。
もう1つは、最終レポートです。 これは、関連性、事実性、引用の根拠、表現、統合の質などを見ます。
評価プロトコルとしては、全体をまとめて評価するholistic judgingと、局所的なステップやチャンクを見るfine-grained judgingを比較しています。また、rubricを使うかどうか、CoTを入れるかどうかも比較しています。
現在の LLM-as-a-Judge は十分に信頼できるとは言いにくい
Table 1では、各モデルがprocess-level reasoning、tool use、outcome-level report qualityの失敗をどれくらい検出できたかが示されています。
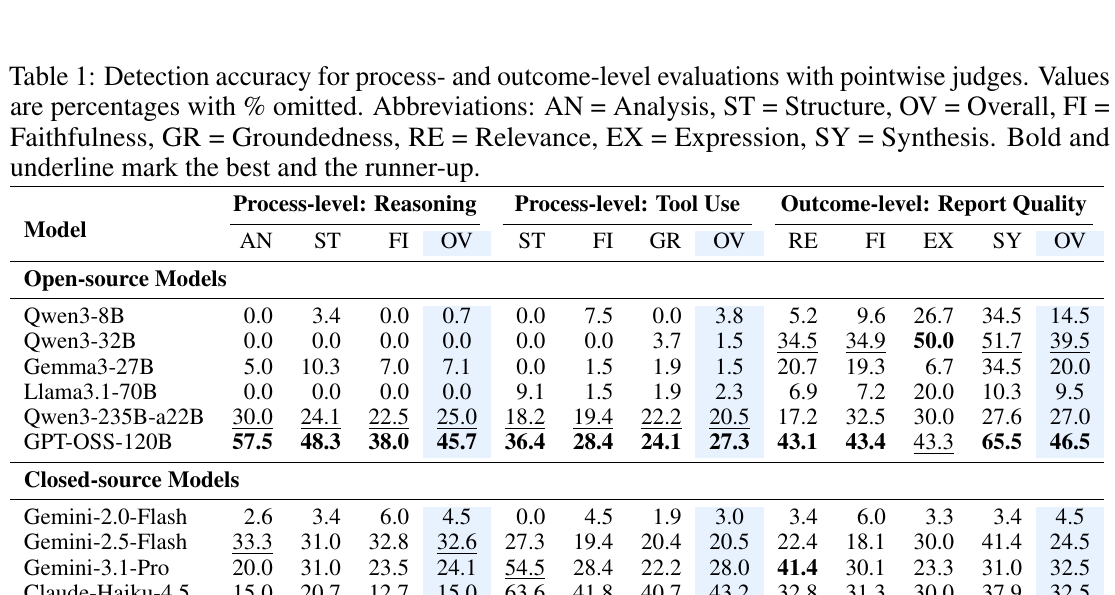
Table 1のpointwise評価では、最良のoverall scoreでも、reasoningは45.7%、tool useは54.5%、report qualityは47.5%にとどまっています。 論文のAbstractでも、現在の LLM-as-a-Judge は推論、ツール使用、レポート品質の失敗に対して、全体精度が55%未満であり、特に証拠検証が弱いと述べています。
また、どの失敗に強いかはモデルによって異なります。Tool-useのstructure errorは比較的検出しやすい一方で、groundednessやfaithfulnessの失敗は難しい傾向があります。最終レポートでも、relevance、faithfulness、expression、synthesisのどれに敏感かはモデルごとに違います。
REFLECTは、こうした違いを項目ごとに細かく見るためのベンチマークです。
細かく見る評価は、全体評価より失敗を見つけやすい
Figure 3では、評価プロトコルの違いが示されています。
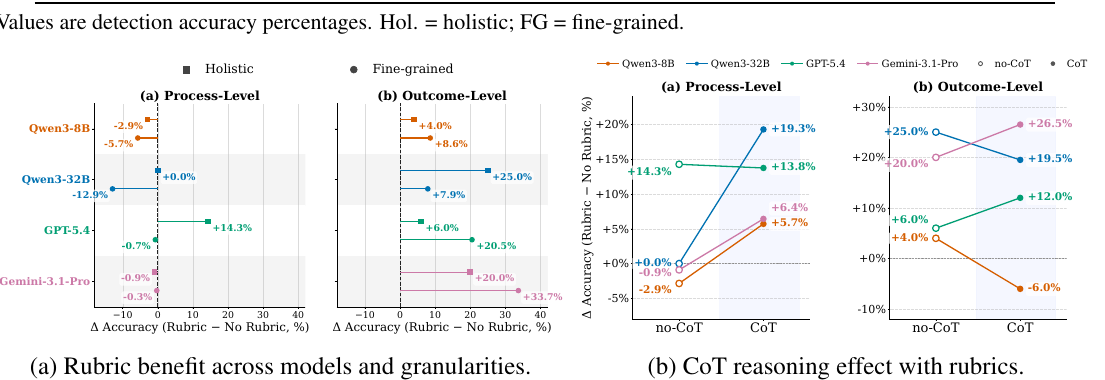
Table 2を見ると、fine-grained judgingはholistic judgingより一貫して検出精度を改善しています。
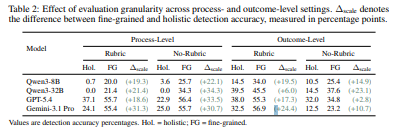
process-levelとoutcome-levelの両方で改善があり、設定によっては30ポイントを超える差が出ています。 これは、長い実行ログや長いレポート全体を見せると、局所的な失敗が埋もれてしまうためです。
たとえば、10ページ分のレポートの中に1つだけ引用ミスがあるとします。全体としてはよく書けているように見えるため、holisticな評価では見落とされるかもしれません。
一方、fine-grained評価では、問題のある段落やステップだけを見せるので失敗が見えやすくなります。
ただし、rubricやCoTの効果は単純ではありません。 論文では、rubricはoutcome-levelでは比較的一貫して改善しますが、process-levelでは効果が混在し、特に弱いジャッジでは負担になる場合があります。長いログから複数の証拠を追い、複数軸でスコアを付ける必要があるため、モデルが十分に強くないと、rubricが助けではなくノイズになる場合があります。
どの失敗を見落としやすいのか
Figure 4では、GPT-5.4とGemini-3.1 Proについて、失敗タイプごとの検出精度が示されています。
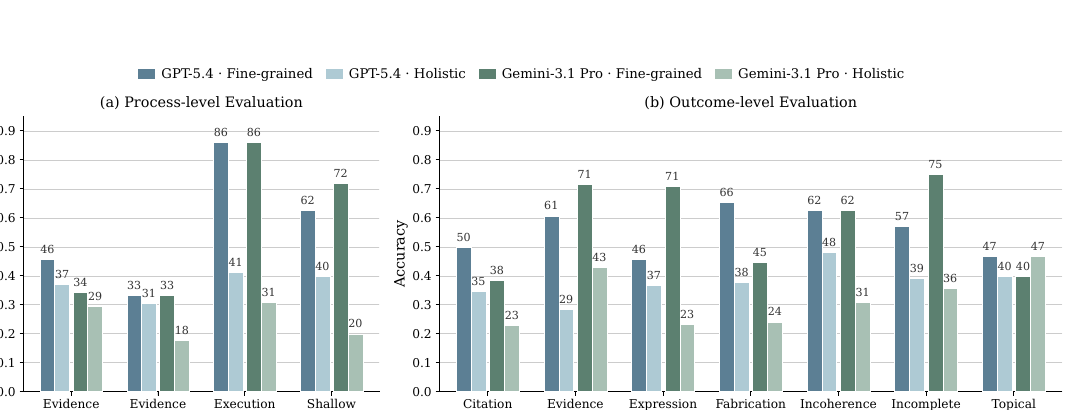
ここで分かるのは、fine-grained評価とholistic評価にはそれぞれ得意な失敗があることです。
fine-grained評価は、局所的な失敗に向いています。たとえば、Execution Stagnation、Evidence Omission、Expression Quality、Incomplete Coverageのように、特定のステップや特定の回答チャンクに現れる失敗です。
一方で、holistic評価の方が見つけやすい場合もあります。たとえば、Shallow ReflectionやTopical Misalignmentのように、全体の流れや目的とのずれを見ないと分かりにくい失敗です。
局所的なミスはfine-grainedで見えやすい。 全体の構造的なずれはholisticで見えやすい。 という結果になっています。 評価単位の選び方そのものがジャッジ性能を大きく変えることを示しています。
Best-of-Nではさらに難しくなる
Figure 5では、Best-of-N選択とコスト・性能の関係が示されています。
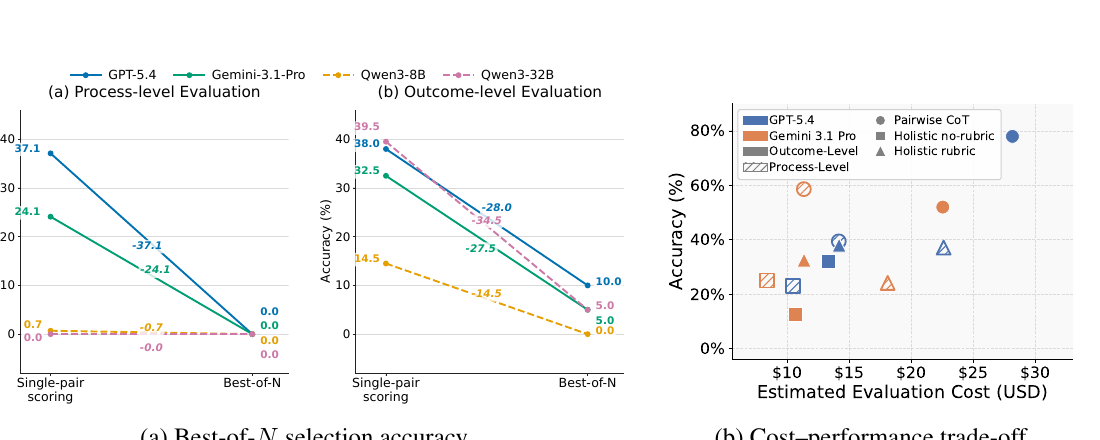
Single-pair scoringでは、元の実行と失敗入りの実行を1対1で比べます。 Best-of-Nでは、元の実行に加えて、複数の失敗入り候補をまとめて見せ、その中から最もよいものを選ばせます。
結果として、Best-of-Nでは精度が大きく下がっています。特にprocess-levelで低下が大きいです。長い実行ログを複数比較しながら、推論、ツール使用、証拠の流れを追う必要があるためです。
コスト面では、高コストな設定ほど精度が上がる傾向はあります。ただし、単に高いモデルを選べばよいわけではありません。論文では、信頼できるジャッジ評価には、モデルの能力、プロトコル設計、評価単位、コストのバランスが必要だと述べています。
この論文で示されていること
この論文で示されているのは、 LLM-as-a-Judge は便利だが、そのまま信頼してよいわけではない、ということです。
エージェントの評価では、最終レポートだけでなく、途中の検索やツール使用や証拠統合も評価する必要があります。ところが、その評価を LLM-as-a-Judge に任せる場合、ジャッジ自身がどの失敗を検出できるのかを調べなければなりません。
REFLECTは、そのために、制御された失敗を入れたペアを作ります。
元の実行。 局所的な失敗を入れた実行。 失敗タイプ。 失敗位置。
この4つで確認をすることで、 LLM-as-a-Judge が本当に失敗を見抜けるかを調べます。 その実験結果として、現在の LLM-as-a-Judge には限界があり、全体精度は高くなく、失敗タイプごとの差も大きくなっていました。fine-grained評価やrubricやCoTの効果も状況によって変わることがわかりました
限界
論文では、REFLECT自体の限界も述べています。
REFLECTは意図的に作られた設定を使っています。そのため、現在のエージェントの実行ログや既存研究からよく見られる失敗については見ることができますが、あらゆるドメイン固有の失敗、自然発生的な失敗、対話的な失敗を網羅するものではありません。
また、あくまでジャッジの挙動を測定しやすくするためのものであり、自然に起きるエージェント失敗の人間監査を置き換えるものではありません。さらに、ジャッジモデルやエージェントが進化するにつれて、REFLECTも新しい実行ログ、失敗タイプ、評価モデルで更新する必要があると述べられています。
まとめ
Time to REFLECT は、Deep research agentを評価する LLM-as-a-Judge の信頼性を調べるための論文です。
REFLECTは、品質確認済みのエージェント実行ログと最終レポートに対して、制御された局所的な失敗を挿入し、ジャッジが失敗を含まない参照実行を正しく高く評価できるかを測ります。これにより、LLM-as-a-Judgeが推論、ツール使用、証拠利用、最終レポート品質のどの失敗を見抜けて、どの失敗を見落とすのかを細かく分析できます。